
大数据毕业设计Flink+Hadoop+Hive地铁客流量可视化 地铁客流量预测 交通大数据 地铁客流量大数据 交通可视化 机器学习 深度学习 人工智能 知识图谱 数据可视化 计算机毕业设计
大数据毕业设计Flink+Hadoop+Hive地铁客流量可视化 地铁客流量预测 交通大数据 地铁客流量大数据 交通可视化机器学习 深度学习 人工智能 知识图谱 数据可视化 计算机毕业设计
河北传媒学院
本科毕业论文开题报告
| 专业 | 小四号宋体 | 班级 | 小四号宋体 | |
| 姓名 | 小四号宋体 | 学号 | 小四号宋体 | |
| 指导教师 | 小四号宋体 | |||
| 题目 | 基于hadoop+spark的深圳市地铁运营的分析与可视化 | |||
| (1.内容包括:课题的来源及意义,国内外发展状况,本课题的研究目标、内容、方法、手段及进度安排、实验方案的可行性分析和已具备的实验条件、具体参考文献等。2.撰写要求:字体为宋体、小四号,字数不少于1500字,1.5倍行距。) 课题的来源及意义 首先,随着城市轨道交通的快速发展,地铁运营数据量也在急剧增加。这些数据包含了乘客流量、车站设施、列车运行等各种信息,对于地铁运营管理具有重要的参考价值。然而,如何有效地处理、分析和可视化这些数据,以提供更优质的服务和更高效的运营管理,是当前亟待解决的问题。 其次,Hadoop和Spark作为当前大数据处理领域的两大主流技术,具有强大的分布式存储和处理能力,可以处理大规模的数据集。同时,它们还提供了丰富的数据分析工具和算法库,可以用于数据挖掘、机器学习、可视化等领域。因此,将Hadoop和Spark应用于地铁运营数据分析与可视化,可以充分发挥其优势,提高数据分析的效率和准确性。 最后,深圳市作为我国南方重要的城市之一,地铁已成为城市交通的重要组成部分。对深圳市地铁运营进行分析和可视化,有助于了解地铁乘客流量、车站设施状态、列车运行情况等信息,为地铁运营管理提供科学决策依据。同时,也可以为其他城市轨道交通运营管理提供参考和借鉴。 国内外发展状况 国内发展状况: 在中国的地铁运营领域,近年来逐渐开始应用大数据技术进行数据分析与可视化。例如,深圳市地铁集团与某高校合作,利用Hadoop和Spark构建了地铁运营数据分析与可视化平台。该平台通过对地铁运营数据(如乘客流量、车站设施状态、列车运行情况等)进行采集、存储和分析,实现了以下功能: (1)数据可视化:通过将数据分析结果以图表、图形等方式展示,为地铁运营管理提供直观、易懂的数据支持。例如,通过热力图展示各站点乘客流量情况,以便更好地调配车辆和人员资源。 (2)趋势预测:通过对历史数据的分析,利用机器学习算法预测未来一段时间内的乘客流量、车站设施状态等趋势,以便提前做好运营计划和资源调配。 (3)异常检测:通过数据挖掘和异常检测算法,及时发现车站设施故障、异常天气影响等潜在风险,以便及时采取措施保障运营安全。 国外发展状况: 在国外地铁运营领域,大数据技术的应用也得到了快速发展。例如,伦敦地铁公司利用Hadoop和Spark对地铁运营数据进行分析和可视化,实现了以下功能: (1)路径规划:通过分析乘客流量和车站设施情况,为乘客提供更快速、便捷的路径规划建议。 (2)安全监控:通过对车站和列车运行数据进行实时监控和分析,及时发现安全隐患和异常情况,提高运营安全性。 (3)乘客流量预测:通过对历史数据的分析,预测未来一段时间内的乘客流量趋势,以便更好地调配车辆和人员资源。 本课题的研究目标
内容
方法、手段
进度安排 1.选题开题 选题阶段:2023年09月04日—2023年10月31日 开题阶段:2023年11月01日—2023年11月15日 2.设计制作 初步设计阶段:2023年11月16日—2023年12月15日 整体设计阶段:2023年12月16日—2024年01月15日 完成系统设计:2024年01月16日—2024年02月10日 3.撰写论文 论文初稿:2024年02月11日—2024年2月底 论文二稿:2024年03月01日—2024年3月31日 论文终稿:2024年04月01日—2024年4月20日 4.毕业答辩 毕业答辩时间:2024年4月底 实验方案的可行性分析 经济可行性 成本效益:该系统的开发和实现需要一定的成本,包括人力、物力和财力等方面的投入。然而,相对于地铁运营带来的社会效益和经济效益,该系统的投入是值得的。通过该系统,地铁运营公司可以更好地了解地铁运营状况,优化资源分配,提高运营效率和服务质量,从而增加收益。 经济效益:该系统的应用可以带来长期的经济效益。通过对地铁运营数据的深入分析和可视化展示,地铁运营公司可以更好地了解乘客需求和市场变化,及时调整经营策略,提高市场竞争力。同时,该系统还可以帮助地铁运营公司优化管理流程,降低运营成本,提高工作效率。 法律可行性 法律法规:在开发和实现该系统时,需要遵守相关的法律法规,包括知识产权法、隐私保护法等。此外,还需要了解相关行业标准和规范,确保系统的合规性和可操作性。 隐私保护:该系统涉及到地铁运营数据和其他敏感信息,需要采取措施保护乘客和公司的隐私。建议在系统设计和开发过程中,采用加密技术、访问控制等措施,确保数据的安全性和保密性。 技术可行性 技术架构:基于Hadoop+Spark的大数据处理框架已经得到了广泛的应用,可以满足地铁运营数据的大规模处理和分析需求。同时,可视化技术也日趋成熟,可以实现对数据的直观展示和交互操作。 技术风险:在开发和实现该系统时,可能会遇到一些技术风险和挑战,如数据质量问题、算法复杂度等。建议在系统设计和开发过程中,充分考虑这些问题,并制定相应的解决方案和技术路线。 已具备的实验条件 硬件资源:win10笔记本电脑配置有16G内存、256G固态硬盘(用于存储、计算、开发)。 软件环境:Python、JDK1.8、MySQL、Vmvare、Maven等。 数据资源:实验环境中需要具备深圳市地铁运营的相关数据资源,包括客流量、车次、能耗、设备维护需求等数据。这些数据可以通过地铁运营公司提供或通过公开数据接口获取。 开发工具:IDEA、Pycharm、Navicat等。 知识储备:黑马大数据系列课程、csdn网站、github等。 具体参考文献 [1]姚明亮,周刚,张龙浩,欧泽波.基于三维数字化的设备绝缘状态可视化监测模型[J].液压气动与密封,2023,43(02):7-11+15. [2]李怀亮.基于可视化学习活动的混合式教学策略实践[J].现代信息科技,2023,7(03):195-198.DOI:10.19850/j.cnki.2096-4706.2023.03.046. [3]Qin Zhicong,Pan Younghwan. Design of A Smart Tourism Management System through Multisource Data Visualization-Based Knowledge Discovery[J]. Electronics,2023,12(3). [4]邵怡敏,赵凡,王轶,王保全.基于区块链技术及应用的可视化研究综述[J/OL].计算机应用:1-12[2023-02-25].http://kns.cnki.net/kcms/detail/51.1307.TP.20230117.1258.004.html [5]李恒升,元保军,常越.气象数据三维可视化产品应用研究[J].气象与环境科学,2023,46(01):106-111.DOI:10.16765/j.cnki.1673-7148.2023.01.014. [6]杨玲,刘珺婷,张倩.公众气象服务可视化传播的现状与发展探析[J].湖南大众传媒职业技术学院学报,2022,22(04):15-18+85.DOI:10.16261/j.cnki.cn43-1370/z.2022.04.004. [7]初润洁,蒲东燕.重庆方言特色词汇可视化档案建设的路径分析[J].新西部,2022(12):105-108. [8]刘强,张旭.地方高校智慧校园可视化建设探讨——以凯里学院为例[J].凯里学院学报,2022,40(06):94-99. [9]张皓,吴梦洁,陈星宇,杨玉辉,胡婉慈,张萌,施越,龙思颖,曹钰,黄仙红.整合视域下卫生服务“以人为本”的语义解构、建构与实践指引——基于Python爬虫搜索的文本分析[J].中国卫生政策研究,2022,15(12):9-17. [10]康卿彬,张卫同,贾舵,郭嘉淞.基于虚拟现实技术的网络运维可视化系统设计与实现[J].智能建筑与智慧城市,2022(12):142-144.DOI:10.13655/j.cnki.ibci.2022.12.041. [11]曾琦,肖燕玲.疫情防控常态化下广播情感类节目的可视化呈现——以泉州广电《主播听你说》为例[J].东南传播,2022(12):142-144.DOI:10.13556/j.cnki.dncb.cn35-1274/j.2022.12.022. [12]常义,何继敏,陈杨,白晓康,王胜于.挤出成型可视化技术的进展[J].塑料,2022,51(06):94-98+105. [13]梁融凌,念其锋.基于Python爬虫的胡润百富榜数据可视化分析[J].电脑与信息技术,2022,30(06):46-50.DOI:10.19414/j.cnki.1005-1228.2022.06.031. [14]林小鹏.可视化协同管理在工程建设管理领域的应用[J].中国建设信息化,2022(23):66-67. | ||||
| 选题是否合适: 是 否 课题能否实现: 能 不能 指导教师:(签字) 年 月 日 | 选题是否合适: 是 否 课题能否实现: 能 不能 指导小组组长:(签字) 年 月 日 | |||

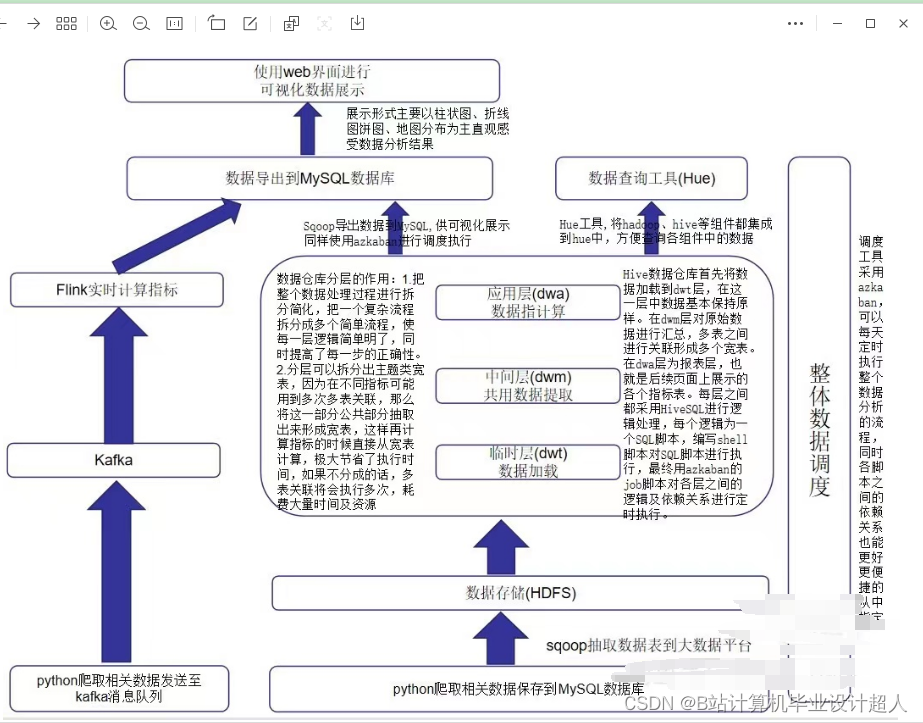
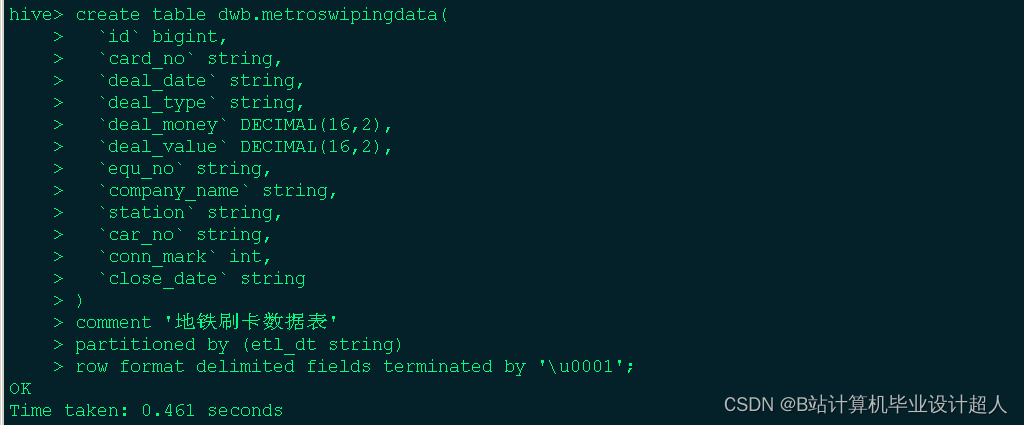

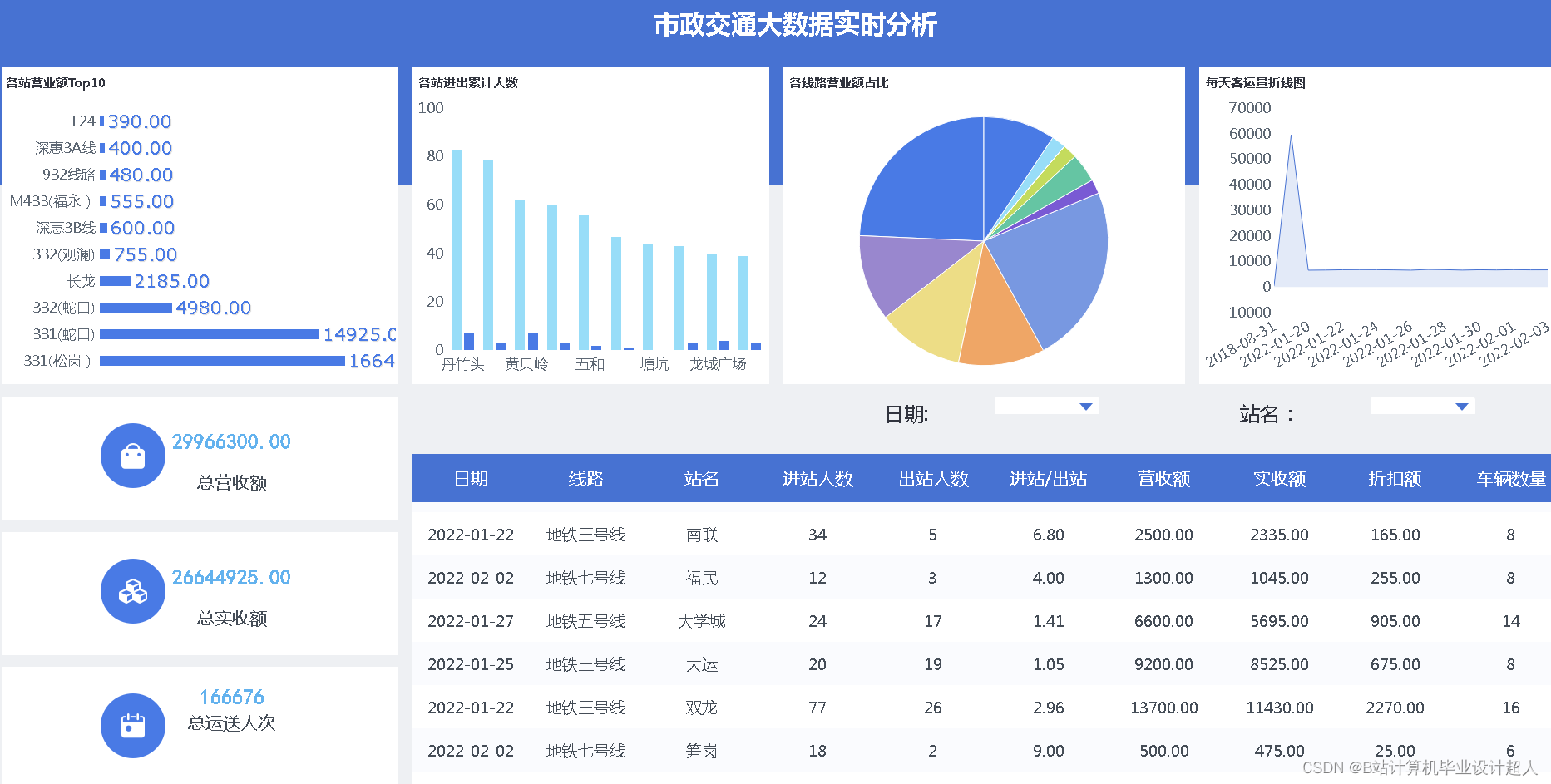
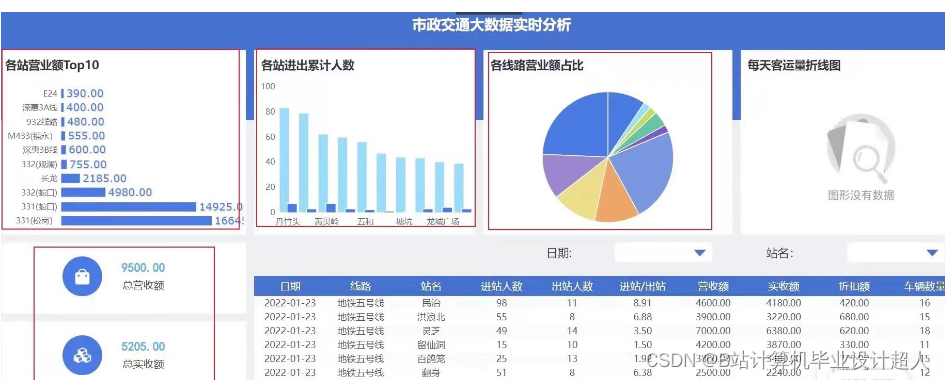
以下是一个简单的地铁客流量预测的 Python 代码示例,使用 LSTM 模型:
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import LSTM, Dense
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
# 读取地铁客流量数据集
data = pd.read_csv("subway_passenger_flow.csv")
# 提取客流量数据并进行归一化处理
passenger_data = data['passenger_count'].values.astype(float)
passenger_data = passenger_data.reshape(-1, 1)
scaler = MinMaxScaler(feature_range=(0, 1))
passenger_data = scaler.fit_transform(passenger_data)
# 创建训练集和测试集
train_size = int(len(passenger_data) * 0.8)
test_size = len(passenger_data) - train_size
train, test = passenger_data[0:train_size, :], passenger_data[train_size:len(passenger_data), :]
# 将时间序列数据转换为监督学习问题
def create_dataset(dataset, time_step=1):
dataX, dataY = [], []
for i in range(len(dataset)-time_step-1):
a = dataset[i:(i+time_step), 0]
dataX.append(a)
dataY.append(dataset[i + time_step, 0])
return np.array(dataX), np.array(dataY)
time_step = 100
X_train, y_train = create_dataset(train, time_step)
X_test, y_test = create_dataset(test, time_step)
# 将输入重塑为 [样本数, 时间步, 特征] 的格式
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1)
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], 1)
# 构建LSTM模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(time_step, 1)))
model.add(LSTM(50, return_sequences=True))
model.add(LSTM(50))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
# 训练模型
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=100, batch_size=64, verbose=1)
# 预测客流量
train_predict = model.predict(X_train)
test_predict = model.predict(X_test)
# 反向归一化预测结果
train_predict = scaler.inverse_transform(train_predict)
test_predict = scaler.inverse_transform(test_predict)
# 可视化预测结果
look_back = time_step
trainPredictPlot = np.empty_like(passenger_data)
trainPredictPlot[:, :] = np.nan
trainPredictPlot[look_back:len(train_predict)+look_back, :] = train_predict
testPredictPlot = np.empty_like(passenger_data)
testPredictPlot[:, :] = np.nan
testPredictPlot[len(train_predict)+(look_back*2)+1:len(passenger_data)-1, :] = test_predict
plt.plot(scaler.inverse_transform(passenger_data))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()
在这段代码中,我们首先读取地铁客流量数据集,并对客流量数据进行归一化处理。然后,我们创建了训练集和测试集,并将时间序列数据转换为监督学习问题。接着,我们构建了一个包含多个 LSTM 层的神经网络模型,并对模型进行训练。最后,我们使用训练好的模型对客流量进行预测,并将预测结果进行反向归一化以得到实际客流量预测值,并可视化了预测结果。
请注意,以上代码仅为演示目的,实际应用中需要根据数据特点和需求进行参数调整、模型优化和超参数调整。

基于 Vue 的企业级 UI 组件库和中后台系统解决方案,为数万开发者服务。
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)