

HDFS的架构优势与基本操作
如今,数据正以指数级增长,各行各业都在追求更多的数据存储、高效的数据处理和可靠的数据基础来驱动业务的发展。Hadoop Distributed File System(HDFS)作为Hadoop生态系统的核心组件之一,成为构建可靠的大数据基础的不二选择之一。本文将深入剖析HDFS的架构与优势。
目录
- 写在前面
- 一、 HDFS概述
- 1.1 HDFS简介
- 1.2 HDFS优缺点
- 1.2.1 优点
- 1.2.2 缺点
- 1.3 HDFS组成架构
- 1.4 HDFS文件块大小
- 二、HDFS的Shell操作(开发重点)
- 2.1 基本语法
- 2.2 命令大全
- 2.3 常用命令实操
- 2.3.1 上传
- 2.3.2 下载
- 2.3.3 HDFS直接操作
- 三、HDFS的API操作
- 3.1 配置Windows
- 3.2 HDFS的API案例实操
- 3.2.1 HDFS文件上传
- 3.2.2 HDFS文件下载
- 3.2.3 HDFS文件更名和移动
- 3.2.4 HDFS删除文件和目录
- 3.2.5 HDFS文件详情查看
- 3.2.6 HDFS文件和文件夹判断
- 写在最后
写在前面
如今,数据正以指数级增长,各行各业都在追求更多的数据存储、高效的数据处理和可靠的数据基础来驱动业务的发展。Hadoop Distributed File System(HDFS)作为Hadoop生态系统的核心组件之一,成为构建可靠的大数据基础的不二选择之一。本文将深入剖析HDFS的架构与优势。
一、 HDFS概述
1.1 HDFS简介
HDFS(Hadoop分布式文件系统)是Apache Hadoop框架的一部分,设计用于存储和处理大规模数据集的分布式文件系统。HDFS产生的背景主要是为了满足处理大规模数据的需求。
在过去,传统的文件系统难以处理大规模数据集,因为它们通常只能在单个服务器上存储和操作数据。随着大数据时代的到来,企业和组织面临着巨大的数据规模和复杂性。为了应对这个挑战,HDFS被开发出来作为一个高度可靠和高容量的分布式文件系统。
HDFS的设计目标是能够在廉价的硬件上运行,并且能够容纳上千台机器的集群。它通过将数据切分成多个块并将其分散存储在不同的计算节点上,实现了高吞吐量的数据访问和处理能力。此外,HDFS还提供了故障容错功能,能够自动处理存储节点的故障。
简而言之,HDFS是为了解决大规模数据处理问题而设计的,它提供了高可靠性、高扩展性和高吞吐量的分布式文件系统解决方案。
1.2 HDFS优缺点
1.2.1 优点
- 高容错、高可用、高扩展
- 数据冗余多副本、副本丢失后自动恢复
- NameNode HA、安全模式
- 10K节点规模,通过横向扩展来增加存储容量和处理能力。
- 海量数据存储(高容量)
- 典型文件大小GB~TB,百万以上文件数量,PB甚至EB以上数据规模
- 构建成本低、安全可靠
- 构建在廉价的商用服务器上,降低了存储成本和维护成本。
- 通过多副本机制,提高可靠性
- 提供了容错和恢复机制
- 适合大规模离线批处理
- 流式数据访问
- 数据位置暴露给计算框架
1.2.2 缺点
- 不适合低延迟数据访问
- 对于实时数据访问和低延迟要求较高的场景,HDFS的性能可能不够理想
- 不适合大量小文件存储
- 元数据会占用NameNode大量存储空间
- 磁盘寻道时间超过读取时间
- 不支持并发写入
- 一个文件同时只能有一个写,不允许多个线程同时写
- 不支持文件随机修改
- 仅支持数据追加
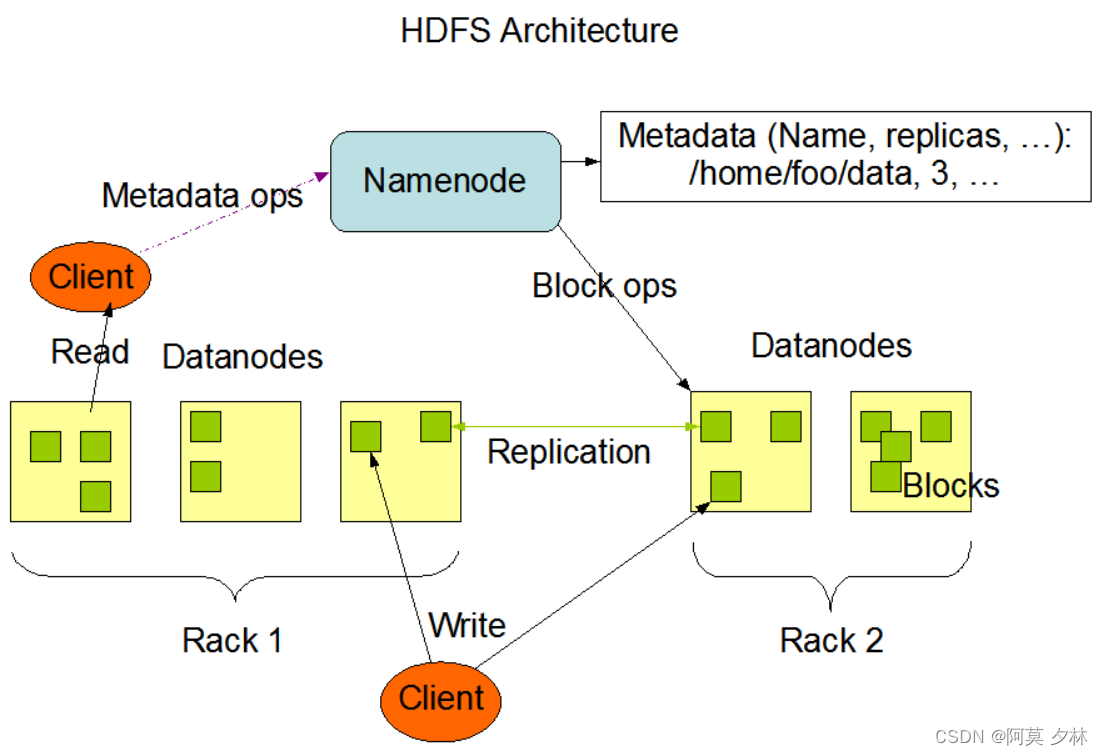
1.3 HDFS组成架构
-
NameNode(nn):
NameNode是HDFS的主节点(Master),负责管理整个文件系统的命名空间和数据块的元数据信息。它维护文件系统的目录结构、文件的安全权限信息和数据块的位置信息等。NameNode还处理客户端的文件系统操作请求,如文件的读写和块的创建、复制和删除等。 -
DataNode(dn):
DataNode是HDFS的工作节点(Slave),负责实际存储文件数据和执行文件系统操作的任务。每个DataNode负责管理一定数量的数据块,并定期向NameNode报告数据块的存储信息。DataNode还处理来自客户端和其他DataNode的读取和写入请求,以及数据块的复制和恢复等。 -
客户端(Client):
客户端是使用HDFS的应用程序。它们通过与Namenode和DataNode进行通信来读取和写入文件。客户端向NameNode请求文件的元数据信息,根据元数据信息确定所需数据块的位置,并从DataNode获取数据。客户端还负责处理文件系统的操作,如创建、删除、重命名和移动文件等。
1.4 HDFS文件块大小
HDFS中的文件在物理上是分成一个个数据块(Block)存储的,块的大小可以通过配置参数(dfs.blocksize)来规定,文件块默认大小是128M。
HDFS文件块的大小选择是根据以下考虑因素:
-
吞吐量:较大的文件块大小在处理大文件时可以提供更高的吞吐量。这是因为较大的文件块减少了磁盘寻道和网络传输的开销,使得数据读取和写入能够更加高效。
-
空间利用:较大的文件块可以减少存储元数据的开销。在HDFS中,每个文件块都有一条元数据记录,较小的文件块可能会导致元数据记录数量增加,增加了存储的开销。
-
并行性:较大的文件块可以提高数据的并行处理能力。在HDFS中,数据块是独立存储和处理的,较大的文件块能够在不同的计算节点上并行处理,从而减少整个作业的执行时间。
较大的文件块适合存储大型文件和批量处理任务,但对于小型文件和实时数据处理,较小的文件块可能更加适合。
Q:为什么HDFS文件块的大小不能太大,也不能设置太小呢?
A: 文件块设置太小,会增加寻址的时间;设置太大,会导致数据处理非常慢。
HDFS文件块的大小设置取决于磁盘的传输速率
二、HDFS的Shell操作(开发重点)
2.1 基本语法
hadoop fs 具体命令 或者 hdfs dfs 具体命令
2.2 命令大全
[amo@hadoop102 hadoop-3.2.4]$ bin/hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] [-q <thread pool queue size>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-crc] [-ignoreCrc] [-t <thread count>] [-q <thread pool queue size>] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] [-t <thread count>] [-q <thread pool queue size>] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge [-immediate]]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-crc] [-ignoreCrc] [-t <thread count>] [-q <thread pool queue size>] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] [-t <thread count>] [-q <thread pool queue size>] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] [-s <sleep interval>] <file>]
[-test -[defswrz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touch [-a] [-m] [-t TIMESTAMP (yyyyMMdd:HHmmss) ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command [genericOptions] [commandOptions]
2.3 常用命令实操
- 创建一个文件夹,用来操作命令
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -mkdir /amoxilin
- help:输出这个命令参数
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -help rm
2.3.1 上传
- -moveFromLocal:从本地剪切粘贴到HDFS
# 创建一个测试文件 test.txt,并输入一些内容
[amo@hadoop102 hadoop-3.2.4]$ vim test.txt
# 使用 moveFromLocal 命令将test.txt文件移动到 HDFS
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -moveFromLocal ./test.txt /amoxilin
- -copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
[amo@hadoop102 hadoop-3.2.4]$ vim test1.txt
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -copyFromLocal test1.txt /amoxilin
- -put:等同于copyFromLocal,生产环境更习惯用put
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -put test1.txt /amoxilin
- -appendToFile:追加一个文件到已经存在的文件末尾
# 创建一个文件test2.txt 并输入内容: 123
[amo@hadoop102 hadoop-3.2.4]$ vim test2.txt
# 将文件 test2.txt 追加到test.txt文件末尾
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -appendToFile test2.txt /amoxilin/test.txt
2.3.2 下载
- -copyToLocal: 从HDFS拷贝到本地
# 将 HDFS 中的test.txt文件copy下来
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -copyToLocal /amoxilin/test.txt ./
[amo@hadoop102 hadoop-3.2.4]$ ls # 查看文件是否拷贝成功 文件夹中有 test.txt,拷贝成功
bin etc lib LICENSE.txt NOTICE.txt sbin test1.txt test.txt wcoutput
data include libexec logs README.txt share test2.txt wcinput
[amo@hadoop102 hadoop-3.2.4]$
- -get: 等同于copyToLocal,生产环境更习惯用get
# 将 HDFS 中的test.txt文件copy下来,并起一个其他的名字比如123.txt
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -get /amoxilin/test.txt ./123.txt
[amo@hadoop102 hadoop-3.2.4]$ ls
123.txt etc libexec NOTICE.txt share test.txt
bin include LICENSE.txt README.txt test1.txt wcinput
data lib logs sbin test2.txt wcoutput
[amo@hadoop102 hadoop-3.2.4]$
2.3.3 HDFS直接操作
- -ls: 显示目录信息
# 查看 HDFS 里amoxilin文件夹的目录结构
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -ls /amoxilin
Found 2 items
-rw-r--r-- 3 amo supergroup 9 2024-03-07 23:33 /amoxilin/test.txt
-rw-r--r-- 3 amo supergroup 49 2024-03-07 23:29 /amoxilin/test1.txt
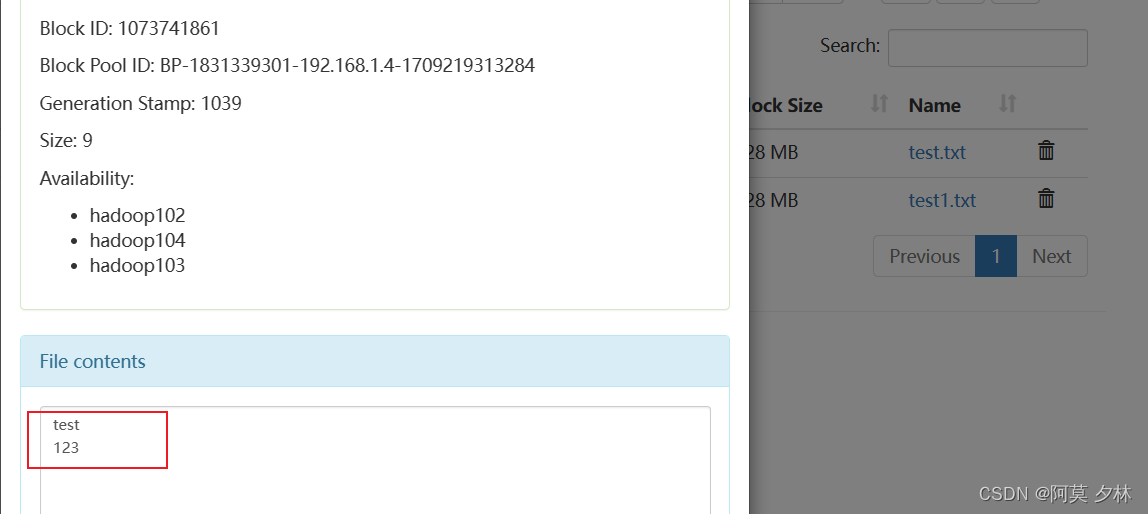
- -cat: 显示文件内容
# 查看某个文件的详细信息
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -cat /amoxilin/test.txt
test
123
- -chgrp、-chmod、-chown: Linux文件系统中的用法一样,修改文件所属权限
# 修改文件的权限
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -chmod 666 /amoxilin/test.txt
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -ls /amoxilin
Found 2 items
-rw-rw-rw- 3 amo supergroup 9 2024-03-07 23:33 /amoxilin/test.txt
-rw-r--r-- 3 amo supergroup 49 2024-03-07 23:29 /amoxilin/test1.txt
# 修改文件的group
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -chown amo:amo/amoxilin/test.txt
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -ls /amoxilin
Found 2 items
-rw-rw-rw- 3 amo amo 9 2024-03-07 23:33 /amoxilin/test.txt
-rw-r--r-- 3 amo supergroup 49 2024-03-07 23:29 /amoxilin/test1.txt
- -mkdir: 创建路径
# 创建文件夹
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -mkdir /csdn
- -cp: 从HDFS的一个路径拷贝到HDFS的另一个路径
# 复制文件
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -cp /amoxilin/test1.txt /csdn
- -mv: 在HDFS目录中移动文件
# 移动文件
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -mv /amoxilin/test.txt /csdn
- -tail: 显示一个文件的末尾1kb的数据
# 查看文件末尾内容
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -tail /amoxilin/test1.txt
欲买桂花同载酒,终不似,少年游!
[amo@hadoop102 hadoop-3.2.4]$
- -rm: 删除文件或文件夹
# 删除
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -rm /amoxilin/test1.txt
Deleted /amoxilin/test1.txt
- -rm -r: 递归删除目录及目录里面内容
# 递归删除
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -rm -r /amoxilin
Deleted /amoxilin
- -u: 统计文件夹的大小信息
# 统计文件夹的大小
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -du -s -h /csdn
58 174 /csdn # 58 是文件大小 文件有三个副本就是58*3=174
# 统计文件夹内各文件的大小
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -du -h /csdn
9 27 /csdn/test.txt
49 147 /csdn/test1.txt
- -setrep: 设置HDFS中文件的副本数量
# 设置hdfs副本数量
[amo@hadoop102 hadoop-3.2.4]$ hadoop fs -setrep 5 /csdn/test1.txt
Replication 5 set: /csdn/test1.txt
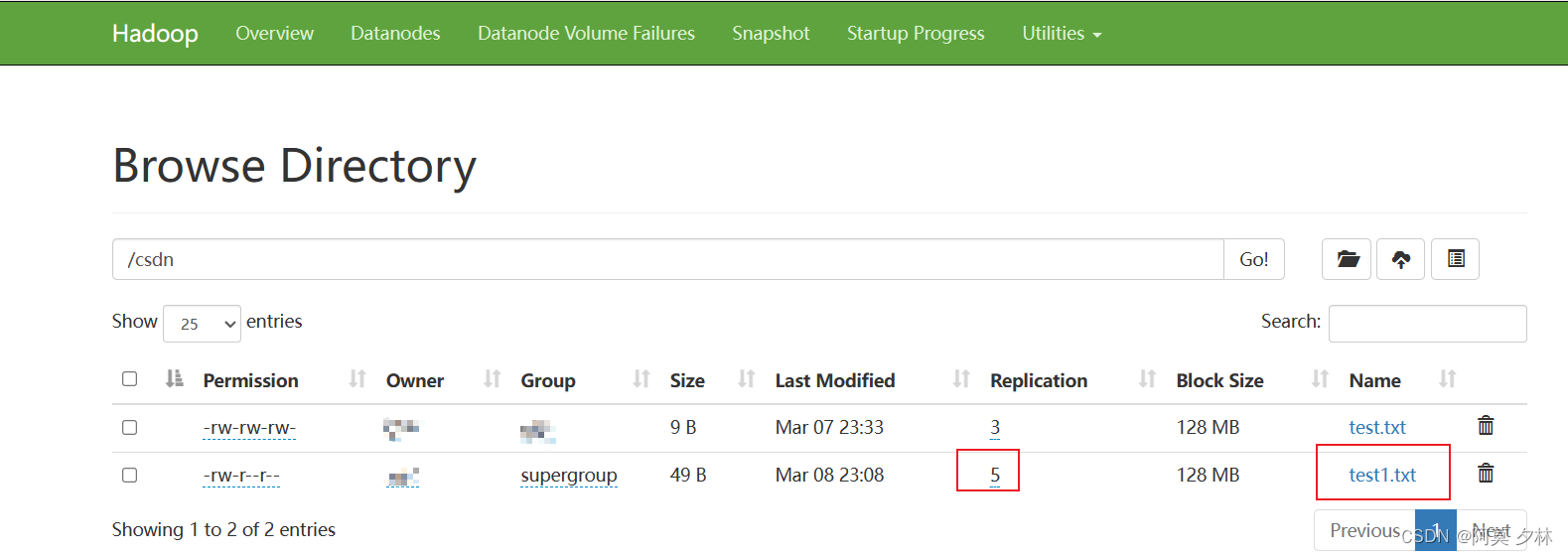
这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到5台时,副本数才能达到5。
三、HDFS的API操作
3.1 配置Windows
- 解压Hadoop安装包到Windows系统
D:\hadoop-3.2.4 - 设置$HADOOP_HOME环境变量指向
D:\hadoop-3.2.4 - 配置Path环境变量
%HADOOP_HOME%\bin - 下载
- 将 hadoop.dll 和 winutils.exe 放入$HADOOP_HOME/bin 文件夹中
3.2 HDFS的API案例实操
- 在IDEA中创建一个Maven工程,并导入相应的依赖坐标以及日志
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
- 创建HdfsClient类
public class HdfsClient {
@Test
public void test() throws IOException, URISyntaxException, InterruptedException {
// 1 获取一个客户端实例
// 参数1:hdfs文件系统地址
// 参数2:配置文件
// 参数3:用户
FileSystem fs= FileSystem.get(new URI("hdfs://hadoop102:8020"), new Configuration(), "amo");
// 2 创建目录
fs.mkdirs(new Path("/amxl"));
// 3 关闭资源
fs.close();
}
}
- 执行程序
3.2.1 HDFS文件上传
- 编写源代码
// 文件上传
@Test
public void testCopyFromLocal() throws URISyntaxException, IOException, InterruptedException {
// 1 获取一个客户端实例
// 参数1:hdfs文件系统路径
// 参数2:配置信息
// 参数3:用户名
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), new Configuration(), "amo");
// 2 使用客户端对象操作HDFS
// copyFromLocalFile(是否删除源数据,是否覆盖目标数据,源数据路径,目标数据路径)
fs.copyFromLocalFile(false, true, new Path("D:\\note.txt"),new Path("/amxl"));
// 3 关闭资源
fs.close();
}
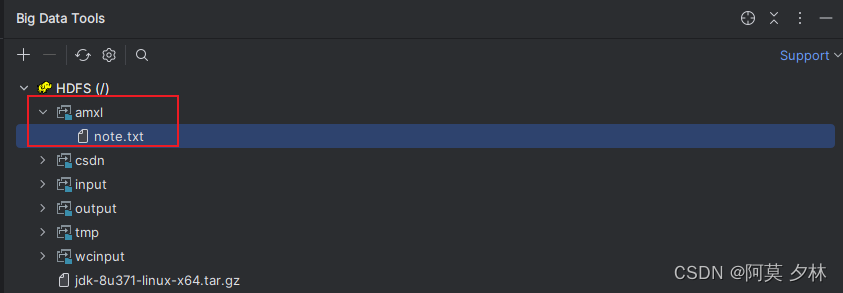
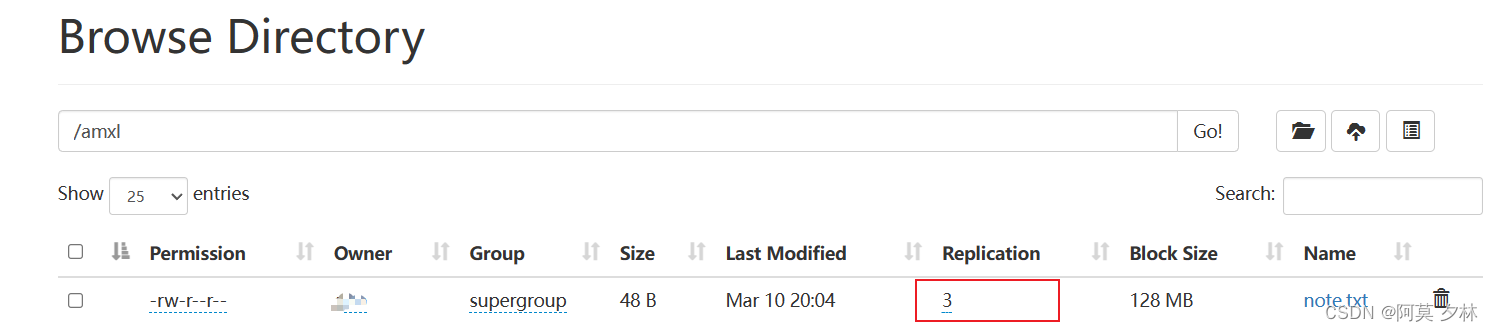
文件默认的副本为3
- 将hdfs-site.xml拷贝到项目的resources资源目录下,重新上传文件
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
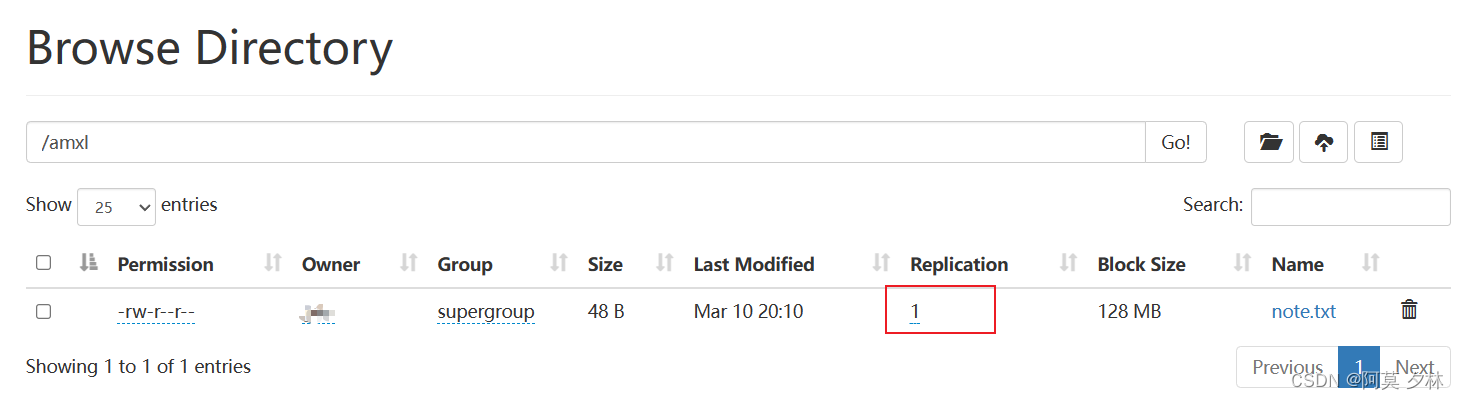
在resources目录下自定义配置文件并设置文件副本数为1,发现此处配置文件参数的优先级是高于默认配置的文件的
- 代码中修改配置
@Test
public void testCopyFromLocal() throws URISyntaxException, IOException, InterruptedException {
Configuration configuration = new Configuration();
// 设置文件副本数为 2
configuration.set("dfs.replication","2");
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "amo");
fs.copyFromLocalFile(false, true, new Path("D:\\note.txt"),new Path("/amxl"));
fs.close();
}
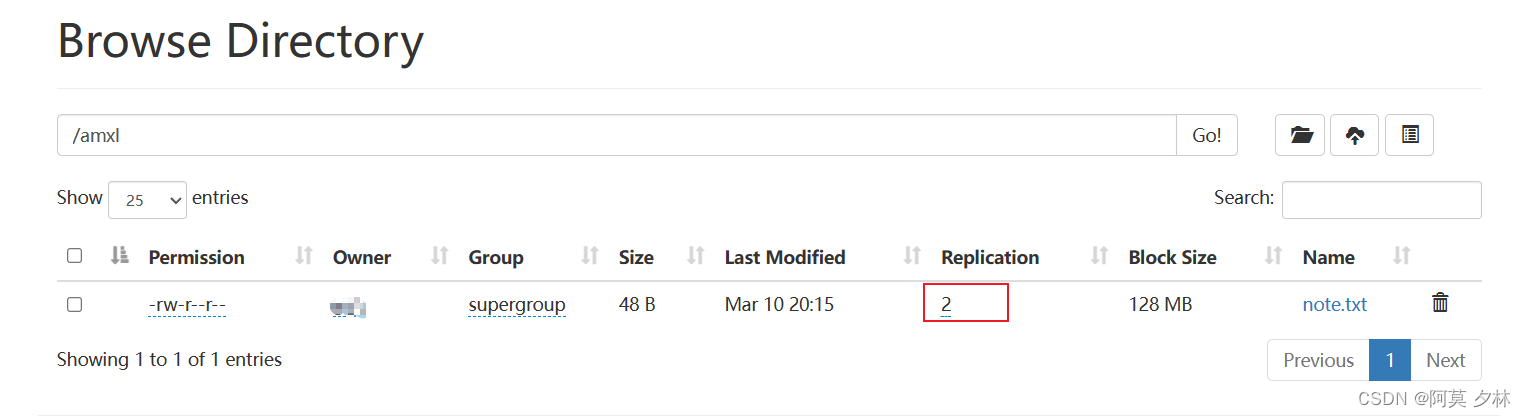
重新上传文件,发现文件的副本数为2
- 小结
参数优先级排序:客户端代码中设置的值 > resources下的用户自定义配置文件 >然后是服务器的自定义配置 >服务器的默认配置
3.2.2 HDFS文件下载
// 文件下载
@Test
public void testCopyToLocal() throws URISyntaxException, IOException, InterruptedException {
// 1 获取配置信息以及加载配置 并获取一个客户端实例
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), new Configuration(), "amo");
// 2 使用客户端对象操作 HDFS 将 note.txt文件下载到本地 D 盘
// copyToLocalFile(是否删除源文件,下载的文件路径,文件下载的目标路径,是否开启文件校验)
fs.copyToLocalFile(false,new Path("/amxl/note.txt"),new Path("D:\\"),true);
// 3 关闭资源
fs.close();
}
3.2.3 HDFS文件更名和移动
// 文件移动和重命名
@Test
public void testRename() throws IOException, URISyntaxException, InterruptedException {
// 1 获取配置信息以及加载配置 并获取一个客户端实例
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), new Configuration(), "amo");
// 2 文件重命名
// rename(源文件名,目标文件名)
fs.rename(new Path("/amxl/note.txt"), new Path("/amxl/note1.txt"));
// 文件移动
// rename(源文件路径,目标文件路径)
fs.rename(new Path("/csdn/test1.txt"), new Path("/amxl/test.txt"));
// 3 关闭资源
fs.close();
}
移动前:
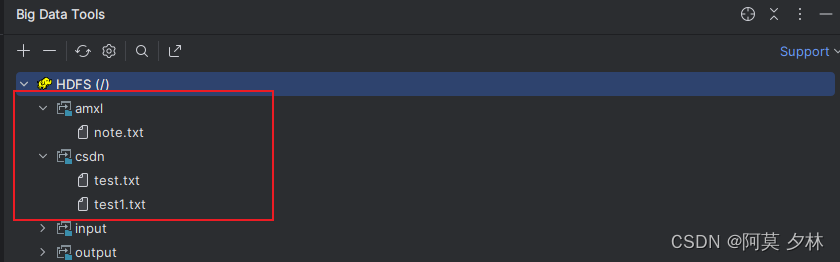
移动后:
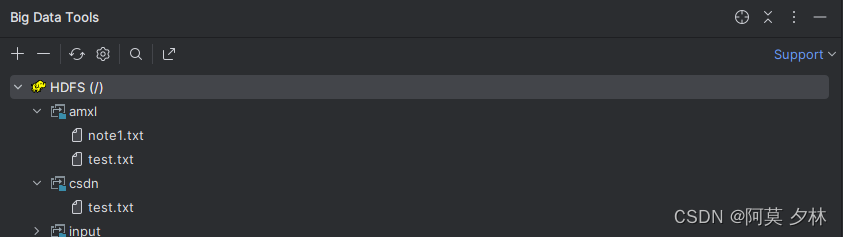
3.2.4 HDFS删除文件和目录
// 删除文件和文件夹
@Test
public void testDelete() throws IOException, URISyntaxException, InterruptedException {
// 1 获取配置信息以及加载配置 并获取一个客户端实例
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), new Configuration(), "amo");
// 2 文件删除
// delete(路径)
// delete(路径,是否递归)
fs.delete(new Path("/amxl/note1.txt"), false);
fs.delete(new Path("/csdn"), true);
// 3 关闭资源
fs.close();
}
删除前:
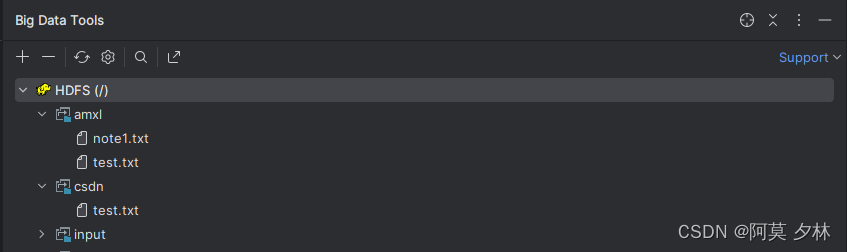
删除后:

3.2.5 HDFS文件详情查看
查看文件名称、权限、长度、块信息
// 查看文件详细信息
@Test
public void testGetFileStatus() throws IOException, URISyntaxException, InterruptedException {
// 1 获取配置信息以及加载配置 并获取一个客户端实例
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), new Configuration(), "amo");
// 2 文件详细信息
// listStatus(路径)
// listStatus(路径,是否递归)
RemoteIterator<LocatedFileStatus> listedFiles = fs.listFiles(new Path("/amxl"), true);
while (listedFiles.hasNext()) {
LocatedFileStatus next = listedFiles.next();
System.out.println(next.getPath());
System.out.println(next.getPermission());
System.out.println(next.getOwner());
System.out.println(next.getGroup());
System.out.println(next.getLen());
System.out.println(next.getModificationTime());
System.out.println(next.getReplication());
System.out.println(next.getBlockSize());
// 获取块信息
BlockLocation[] blockLocations = next.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
// 3 关闭资源
fs.close();
}
// -----------------------------------------------------------------------------------------
// 输出
hdfs://hadoop102:8020/amxl/test.txt
rw-r--r--
amo
supergroup
49
1709910523258
5
134217728
[0,49,hadoop104,hadoop103,hadoop102]
3.2.6 HDFS文件和文件夹判断
// 判断文件夹和文件
@Test
public void testListFiles() throws IOException, URISyntaxException, InterruptedException {
// 1 获取配置信息以及加载配置 并获取一个客户端实例
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), new Configuration(), "guo");
// 2 判断文件夹和文件
// listStatus(路径)
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
// 判断是否是文件
if(fileStatus.isFile()) {
System.out.println("文件:" + fileStatus.getPath().getName());
}else {
System.out.println("文件夹:" + fileStatus.getPath().getName());
}
}
// FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
//
// for (FileStatus fileStatus : fileStatuses) {
// // 判断是否是文件夹
// if (fileStatus.isFile()) {
// System.out.println("文件:" + fileStatus.getPath().getName());
// }
// if (fileStatus.isDirectory()) {
// System.out.println("文件夹:" + fileStatus.getPath().getName());
// }
// }
// 3 关闭资源
fs.close();
}

写在最后
总的来说,HDFS架构的优势和基本操作使其成为构建可靠的大数据基础的理想选择。它的高可靠性、高扩展性和高效的数据访问方式,为处理大规模数据提供了强大的支持,并通过Shell操作和API操作,方便用户管理和操作存储在HDFS中的数据。

基于 Vue 的企业级 UI 组件库和中后台系统解决方案,为数万开发者服务。
更多推荐
 94
94 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)