登录社区云,与社区用户共同成长
邀请您加入社区
通过学习 Isaac Sim 、 Isaac Lab 和 Isaac ROS 在线自主培训课程,从根本上了解机器人开发的核心概念,并探索仿真和机器人学习方面的必备工作流。课程概要:探索 NVIDIA Cosmos™ 平台,包括生成式世界基础模型(WFM)、先进的标记器(tokenizers)、护栏机制(guardrails),以及加速数据加工和精选流程,旨在加速物理人工智能的开发。课程概要:学习软
你还可以查看“HISTOGRAMS”选项卡来了解模型参数分布的变化,“GRAPHS”选项卡来查看计算图结构(虽然对于Keras用户来说通常不需要手动查看),以及“DISTRIBUTIONS”和“PROFILER”等其他选项卡来获取更多信息。注意:在上面的代码中,tf.summary.image的第三个参数step通常用于指示训练步骤,但在仅可视化图像时可能不是必需的。在训练脚本中,需要使用Tens
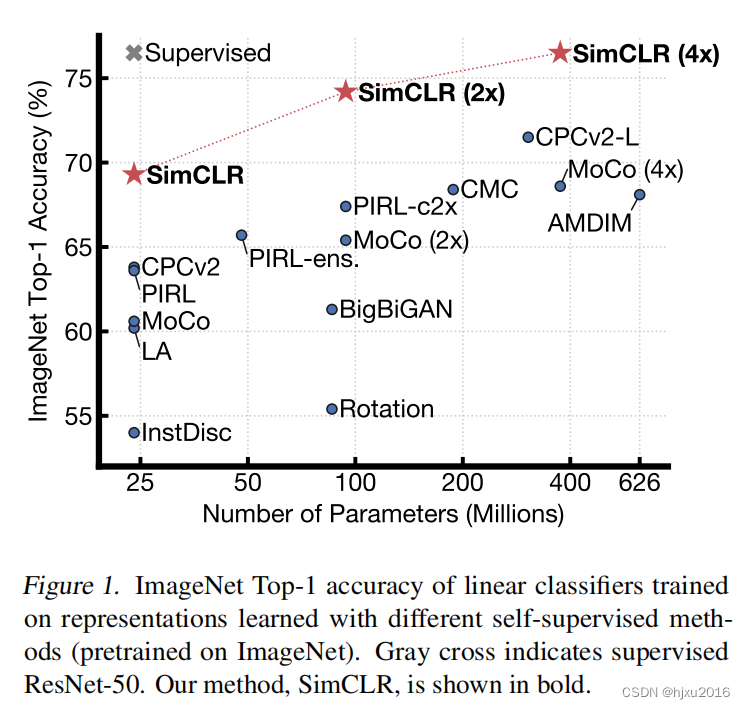
自监督学习SimCLR论文理解
一个著名的说法是:“问题不在于智能机器是否能有任何情绪,而在于机器是否能在没有情绪的情况下变得智能。”
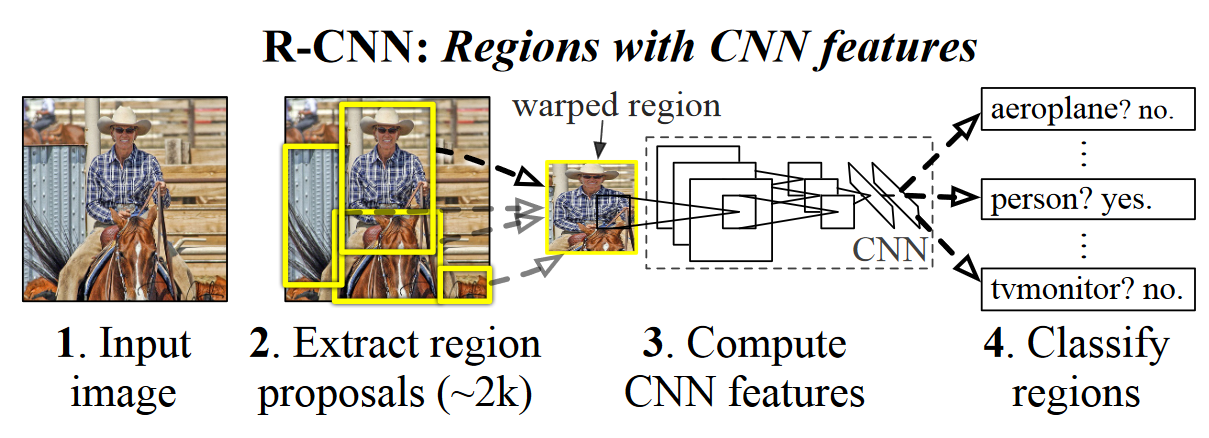
Anchor box是怎么作用到RPN中的?网络是如何学习到分类和回归的呢?在RPN训练时,传给它的不是全部的特征图吗?是如何实现从全部特征图中将特定选择好的256个anchor box放入其中进行训练的呢?
在自动视力检测中,手势识别是关键。
在捕捉长距离依赖关系上的优势,从而这种创新的结合不仅提升了模型的预测精度,还优化了性能和训练效率,使其在序列分析任务中展现出卓越的能力。例如,最新的混合架构模型在Nature子刊上发表,以及模型,都是这一领域的杰出代表。
python保存float类型的小数的位数的三种方法
SCI论文各部分的写作原则与注意点
Fixmatch:用一致性和置信度简化半监督学习
空间-降维注意力(Spatial-Reduction Attention,SRA):空间-降维注意力是一种在金字塔视觉变换器(Pyramid Vision Transformer)架构中使用的多头注意力模块,它在注意力操作之前减少了键(K)和值(V)的空间尺度,从而减少了计算/内存开销【17†source】。通道注意力模块(Channel Attention Module):通道注意力模块(CAM
以下是一个为期两个月的暑假大模型学习计划,旨在帮助您为寻找大模型实习岗位做好准备:第1周:基础知识储备第1天至第3天:学习线性代数、概率论和统计学基础。第4天至第5天:了解机器学习的基本概念,包括监督学习、非监督学习和强化学习。第6天至第7天:熟悉Python编程,特别是数据处理和机器学习库(如NumPy, Pandas, Scikit-learn)。第2周:深度学习入门第1天至第3天:学习神经网
第二个问题有可能是你之前工程打包的文件和当前Unity工程文件起了冲突,导致你第二个工程没有权限去删除上一个工程的minigame,需要你手动去删除。第一个问题可以不用管,这个不影响,这个错误,但是可以正常运行,而且功能没有任何影响,只是控制台不断报错。或者是你重新再另创一个文件夹,导出到新建的文件夹就行了。删除掉这个,然后再重新打包就行了。
学习PLC编程、工业通信协议(如Modbus、OPC UA)、工业机器人控制,以及物联网(IoT)平台开发(如ROS、工业4.0框架)。深入MES(制造执行系统)、SCADA(数据采集与监控系统)开发,学习数字孪生技术及AI在制造中的应用(如缺陷检测算法、生产优化模型)。掌握EDA工具(如Cadence)、数据分析工具(MATLAB、Python的Pandas/Numpy),以及版本控制工具(Gi
以上笔记介绍了五个 Python 代码示例及解析,涵盖文件监控、配置管理、日志分析、简单加密和大文件处理场景:文件监控:通过 MD5 哈希对比检测文件变更,适合轻量级监控但存在效率和安全性局限。配置管理:基于configparser操作 INI 文件,实现读写和默认值机制,需补充异常处理。日志分析:逐行统计关键字次数,支持扩展但对格式敏感,可优化大小写和多类型统计。简单加密:使用 XOR 运算加密
Python 的错误和异常可以分为多个类别,了解这些类别有助于更好地调试和处理错误。以下是 Python 中常见报错信息的归类和分析。在代码执行前被解析器捕获的错误,通常是由于代码不符合 Python 语法规则。常见子类:示例:2. 异常 (Exceptions)程序运行时发生的错误,即使语法正确也可能发生。:访问对象不存在的属性2.2.2 与索引和键相关:序列下标超出范围:字典中不存在的键2.2
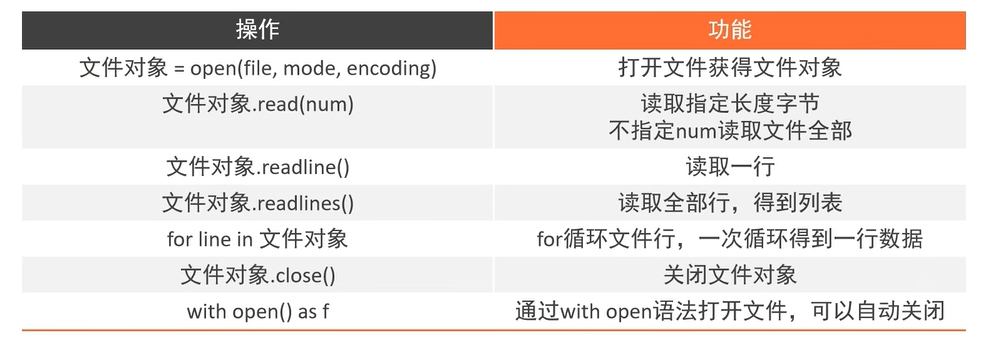
1.了解文件操作的作用2.掌握文件的打开、读取、关闭操作包括:打开、关闭、读、写。# 87节——案例练习:单词计数"""演示读取文件,进行课后练习"""# 打开文件f=open("D:/87节-案例练习:单词计数:itheima/word.txt","r",encoding="utf-8")# 方式1:读取全部内容,通过字符串count方法统计itheima的单词数量print(f"itheima
本文介绍了使用Python替代MATLAB进行滤波器设计的方法。代码示例展示了如何设计IIR椭圆滤波器和FIR凯塞窗滤波器,包含参数设置、阶数估算和性能分析。关键点包括:1)利用scipy.signal模块的ellipord和firwin函数;2)滤波器阶数计算公式;3)通过freqz分析幅频/相频响应;4)可视化零极点图和群延迟。结果显示Python能有效完成传统MATLAB的滤波器设计任务,提
【代码】python学习---dayday2。
1.1 ToTensor转换# 1. ToTensor转换1.1.1 功能:将 PIL 图像转换为 PyTorch 张量(Tensor),并可视化结果。1.1.2PIL 图像VSPyTorch 张量(1)PIL 图像(原始食材)形式:类似一张 “真实的照片”,以像素矩阵存储,但格式是 Python 的 PIL.Image 对象。特点人类友好:可以直接用 img.show() 显示图像。操作受限:只
这是一篇关于Python爱心表白动画的教程文章。文章展示了一个粉色爱心动画效果图,并提供了完整源代码。该程序使用tkinter库创建窗口,通过数学函数绘制动态爱心图案,实现扩散特效和随机光晕效果。代码中包含详细的注释,用户可自行修改爱心颜色等参数。程序还添加了文字标签显示表白信息,窗口会自动居中显示。这个趣味小工具适合作为惊喜表白或娱乐使用,代码结构清晰,注释完整,便于二次开发。
补充:调整超参数的原因补充:调整超参数的原因补充:关于“验证集”验证集(Validation Set)是机器学习中非常重要的一个概念。
项目是前后端分离的项目~部署在docker上~结合chatgpt~deepseek~cursor~csdn写的有点乱~多多包涵~图书馆快关门啦~1. 根据chatgpt创建一个对应的结构~2.~直接在前端文件下输入打包的命令行打包的文件会生成存放在【dist】文件夹中3.用cursor写的4.6.maven-clean-package:出现jar包就是打包好的文件。6.8.
HDFS,HBase,MapReduce,SparkRDD,SparkSQL
通过DFT计算与AFM表征,作者在Cu(111)上的水合氢离子和甲酸相界面处捕获了FA和水配合物的一些亚稳态结构,因此重构了质子在去质子化过程中的转移途径。作者对Cu(111)上FA-水配合物中FA的去质子化过程进行了爬升图像轻推弹性带(cNEB)计算,能垒的显著降低表明界面水对FA的去质子化有促进作用,是OH键裂解的高效催化剂。DFT计算表明,该过程通过Grotthuss质子转移机制在水-FA配
本文介绍了使用PyTorch构建MLP模型对鸢尾花数据集进行分类的完整流程。实验环境搭建包括导入必要库和加载数据集,数据预处理采用归一化和训练测试集划分。构建的MLP模型包含输入层、隐藏层和输出层,使用ReLU激活函数和交叉熵损失函数,通过SGD优化器进行了20000轮训练。在测试集上达到96.67%准确率,并对模型结构和权重参数进行了可视化分析。实验总结了深度学习的实践经验,包括模型训练、评估和
环境:ubuntu16.04,ros-kinetic,python2,概要:这节课笔记,展示的是,添加车子模型到ros里面,并在rviz显示。资料准备及预处理可参考博客,https://blog.csdn.net/qq_45701501/article/details/116447770。
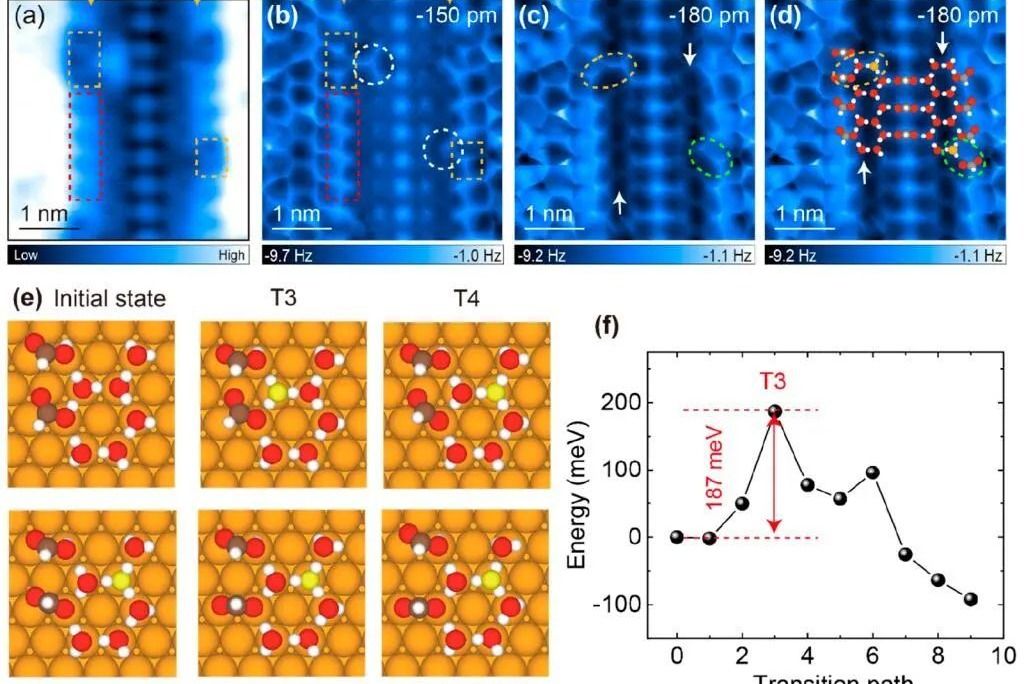
确认Excel列标识正确(字母A/B/C或数字1/2/3):展示A/B两类商品的销售趋势对比(带平滑曲线):呈现A/B两类商品的销售数据堆积对比。支持交互式查看数据点数值。检查文件保存路径写入权限。剩下交给大家探索吧!
今天小编总结归纳了若干个常用的可视化图表,并且通过调用plotly、matplotlib、altair、bokeh和seaborn等模块来分别绘制这些常用的可视化图表,最后无论是绘制可视化的代码,还是会指出来的结果都会通过调用streamlit模块展示在一个可视化大屏,出来的效果如下图所示那我们接下去便一步一步开始可视化大屏的制作吧!
外链图片转存中…(img-jYYuhWEo-1713660971858)][外链图片转存中…(img-vqcVyaa2-1713660971859)]
有关 Impala 中授权的详细信息,包括如何使用存储在元存储数据库中的权限从原始基于策略文件的权限模型切换到 Sentry 服务,请参阅。由于 Impala 和 Hive 共享同一个元存储数据库,并且它们的表经常互换使用,因此以下部分详细介绍了 Impala 和 Hive 之间的差异。本节介绍的实例 Impala 和 Hive 具有相似的功能,有时包含相同的语法,但这些功能的运行时语义存在差异。
由于篇幅有限,现将全部代码打包至下方,需要学习的小伙伴可自取。
本文通过。
大数据组件之Hbase学习笔记分享(脑图)
LangFlow与LangChain的协同使用,实现了从快速原型到工业级部署的无缝衔接。这种低代码+全代码的混合开发模式,正在重新定义LLM应用的开发范式。建议开发者根据项目阶段灵活选择工具:早期验证用LangFlow快速迭代,复杂场景回归LangChain深度定制。如何学习大模型 AI?由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。“最先掌握AI的人,将
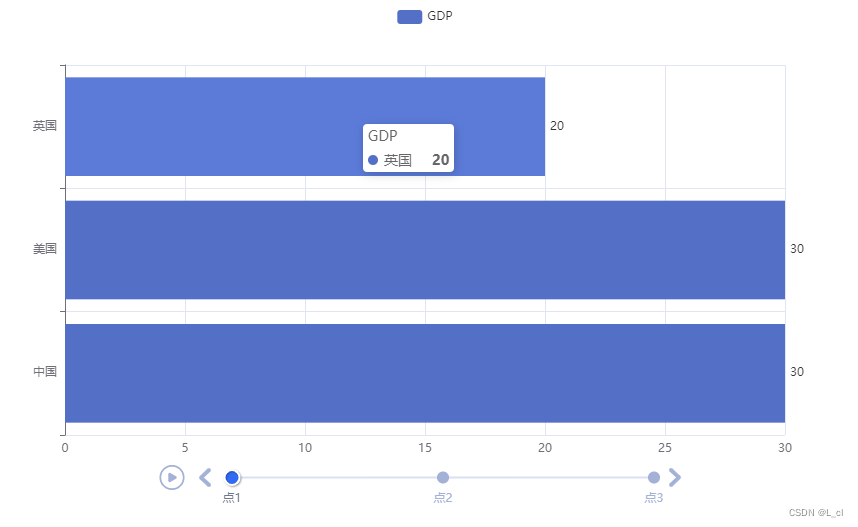
爬取全国医院数据并可视化分析1、数据采集:用python爬虫获取所需要的数据,使用到requests、bs4、re模块等。2、数据存储:建立数据库连接,将爬取到的数据储存在mysql数据库中。3、数据清洗、处理与分析:将存储的数据进行数据清洗、处理与分析。4、数据可视化:利用Flask框架、pyecharts、WordClound来实现数据可视化。5、前端框架:Layui。
什么是A/B测试?说白了就是中学生物实验里常说的控制变量。实验对象分为A组(对照组)、B组(实验组)来测试某个行为的影响。在互联网企业,为了判断某个行为的效益,或者挑选更加合适的方案就会采用A/B测试。A/B测试的核心在于两组样本除了实验条件不一样,其他条件都一样。因此A/B测试依赖如下假设。每个因子水平的数据均呈正态分布案例独立性:样本案例应相互独立方差的同质性:同质性是指各组之间的方差应近
学!学就完事了
注:使用edgeR进行差异表达分析,官方建议最快的方式是subread-featurecounts管线,但其实所有由htseq或featurecounts进行计量的管线(产出read counts),都可以参与到edgeR软件的差异性表达分析。因为RNAseq获取的是RNA的相对表达量,如果有部分基因极度高表达,就会使得样品中的其它基因被误认为低表达,edgeR通过计算TMM值来减少这个效应(no
大家可以关注一下,之后我还会说说redis基础,慢慢过渡到redis与springboot(mybatis)的项目应用,力求详细,同时分享一些开发感悟,如果觉得我这个人写的还不错,可以看看我以前写的,涵盖Java,python,运维系列,还有。顺带提一口,安装redis后,点击redis-server.exe文件,跳出终端,显示如下即成功启动(第二张),点击cil.exe,则可操作redis。可以
下面主要介绍使用微搭低代码平台进行数据展示的学习过程,供各位小伙伴参考。
FlowUs 是一款功能强大的工具,它可以帮助你更高效地组织和管理信息。无论你是用于个人项目管理、团队协作还是知识整理,FlowUs 都能提供便捷的解决方案。FlowUs数据图表是对多维表数据的统计与分析,并支持可视化为多种图表类型,如数据指标、柱状图、折线图、饼图等。FlowUs数据图表教程将详细介绍如何在FlowUs中使用数据图表,包括其支持的类型、插入方法、配置步骤以及各种图表类型的使用和样
在现代数据驱动的时代,实时数据流处理已经成为一种关键技术。实时数据流处理(Real-Time Data Stream Processing)指的是在数据生成时立即处理和分析数据的过程。与批处理不同,实时数据流处理能够在数据生成的瞬间提供即时的分析结果,从而支持及时决策和响应。
ERPNext是一个开源的企业资源计划(ERP)系统,由Frappe Technologies Pvt. Ltd.开发,主要用于帮助中小企业进行全面的业务管理。
🍋🍋🍋🍋在 SQL 面试中,JOIN是高频考点,面试官通常会考察对不同连接类型的理解、应用场景、性能优化以及关联条件的逻辑。
学习目标:大数据技术原理与应用学习内容:2.大数据处理架构Hadoop2.1Hadoop简介和版本演变2.2Hadoop项目结构2.3Linux&Hadoop的安装2.4Hadoop集群的部署和使用学习时间:2022/03/10学习产出:2.1Hadoop简介2.1.1Hadoop简介HADOOP是Apache软件基金会旗下的开源软件,java语言开发,可以支持各种编程语言。两大核心:HDFS+M
首先,用于支持决策,面向分析型数据处理;其次,对多个异构的数据源有效集成,集成后按照主题进行重组,并包含历史数据,而且存放在数据仓库中的数据一般不再修改。数据仓库(Data Warehouse)是一个面向主题的(subject oriented)、集成的(integrated)、相对稳定的(non-volatile)、反应历史变化(time variant)的数据集合,用于支持管理决策(decis
学习
——学习
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net




 NVIDIA AI 技术专区
NVIDIA AI 技术专区


 2048 AI社区
2048 AI社区













 松山湖开发者村综合服务平台
松山湖开发者村综合服务平台


 AI 知识库会话
AI 知识库会话







 DeepSeek技术社区
DeepSeek技术社区

 永洪数据分析社区
永洪数据分析社区