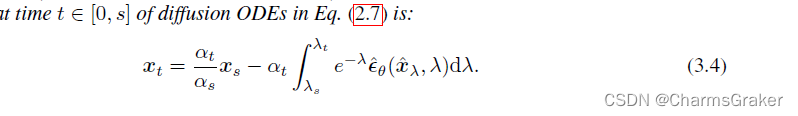登录社区云,与社区用户共同成长
邀请您加入社区
Jmeter是由Apache公司开发的java开源项目,所以想要使用它必须基于java环境才可以;Jmeter采用多线程,允许通过多个线程并发取样或通过独立的线程对不同的功能同时取样。
spei-python 是一个用于计算标准化降水蒸散指数(SPEI)的专业库,适用于气象研究、农业管理和水资源管理等领域
scrapy是一个使用Python语言(基于Twisted框架)编写的开源网络爬虫框架目前由维护。Scrapy简单易用灵活易拓展开发社区活跃,并且是跨平台的。在Linux、MaxOS以及windows平台都可以使用。
解决之前mmaction2配置文件无法跑通视频帧训练的问题。
在终端打开python,查看pytorch版本。我的版本为2.1.2+cu121。解决:查看pypi文档。
C:\Users\你的用户名\.cache\torch\hub\ultralytics_yolov5_master,如果能在线下载的话,可以考虑从这里复制出来,我是在线下载后,将hub,复制到了项目同路径,所以可以用相对路径调用。因为众所周知的网络,该模型无法被在线下载,所以下载文件后,改为本地加载就可以正常运行了。问题描述:跑一个torch项目,代码中执行到加载模型时特别慢,然后报出了网络超时。
K-D树,英文全称为K-dimention tree,是一种存储k维空间中数据的平衡二叉树型结构,主要用于范围搜索和最近邻搜索。K-D树实质是一种空间划分树,其每个节点对应一个k维的点,每个非叶节点相当于一个分割超平面,将其所在区域划分为两个子区域。
关于Anaconda的安装就不介绍了,本文主要介绍spyder中安装 tensorflow。废话少说 直接重点:1、安装好Anaconda之后,找到spyder图标 点击install,等待安装完成(下面是已经安装好了的)接着点击 左边的Environments 找到对应的环境,下载tensorflow包(重点就在这)必须下载这两个包才行(如果全部选中,是不能下载的),...
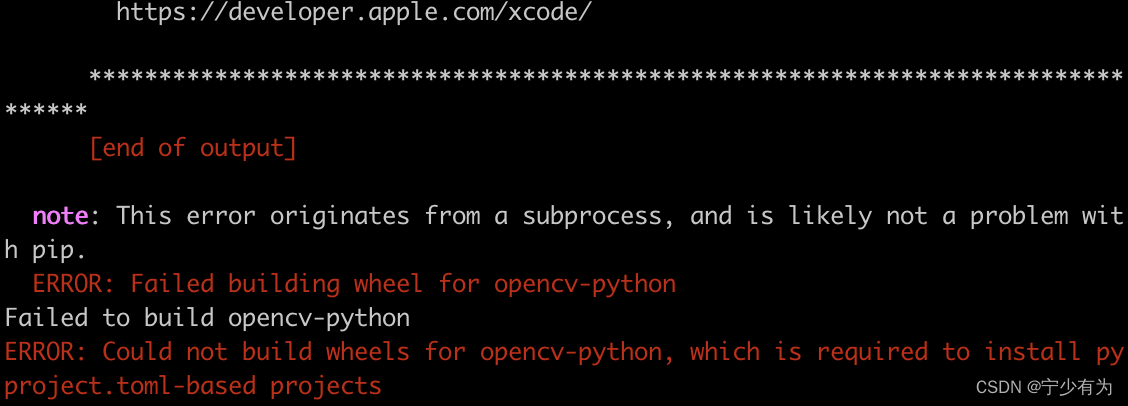
问题:安装opencv-python时,控制台报错,一直装不上,百度了很久都没有解决:报错信息:ERROR: Could not build wheels for opencv-python, which is required to install pyproject.toml-based projects报错截图:解决:访问opencv的镜像文件的网站,下载whl文件安装https://mir
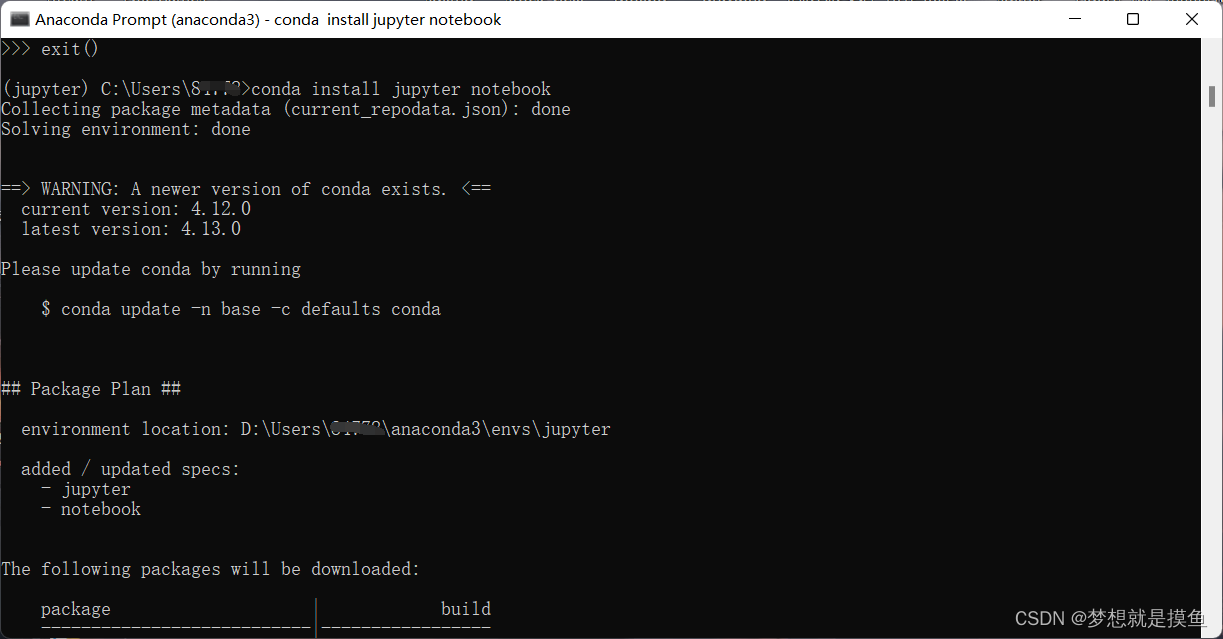
Windows使用Anaconda安装jupyter notebook以及简单使用
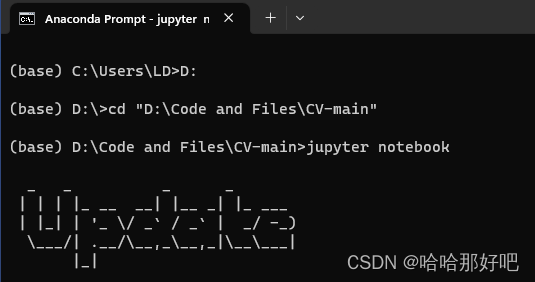
2.进入D盘后输入cd+文件夹名称,可以直接去复制文件位置,如图。3.进入想要打开的文件夹后输入 jupyter notebook。
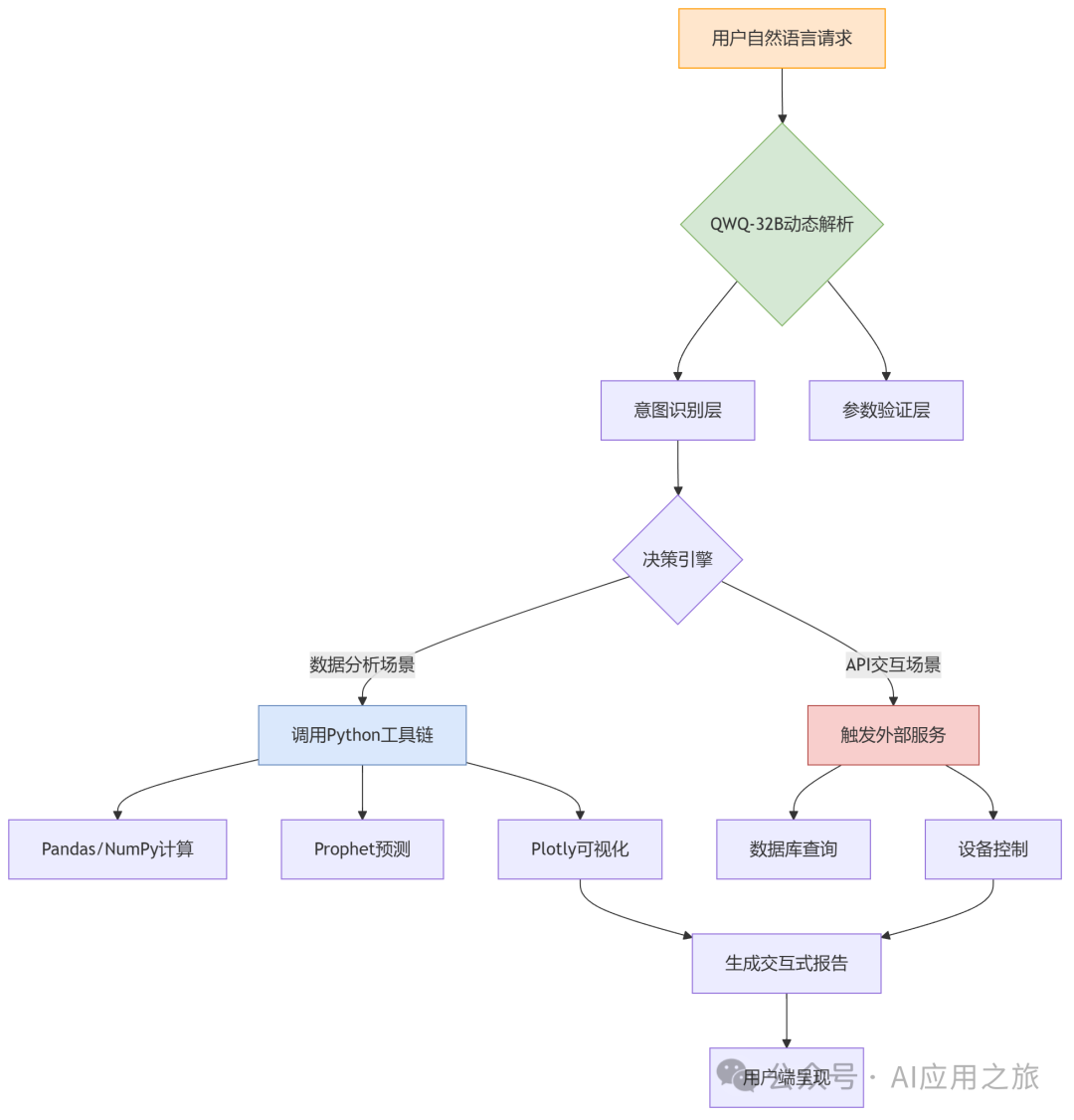
1️⃣:突破训练数据时效限制,实时调用外部知识(如调用Wind金融终端获取最新财报)2️⃣:通过API控制物联网设备(案例:某工厂部署后设备故障响应速度提升23倍)3️⃣:实现「思考-执行-验证」的闭环推理(实测复杂任务完成率从37%→89%):当大模型可主动调用10万+工具时,传统SaaS软件架构将彻底重构!某电商巨头采用QWQ-32B实现:✅:用户问“为什么东北区销量下滑” → 自动调用SQL
我们就简单举一个例子把star_rating为3到4中的positive减去0.25把star_rating小于3的positive减去0.3star_ratingpositive050.98072110.737101250.945672320.729632450.99853530.408589610.65...
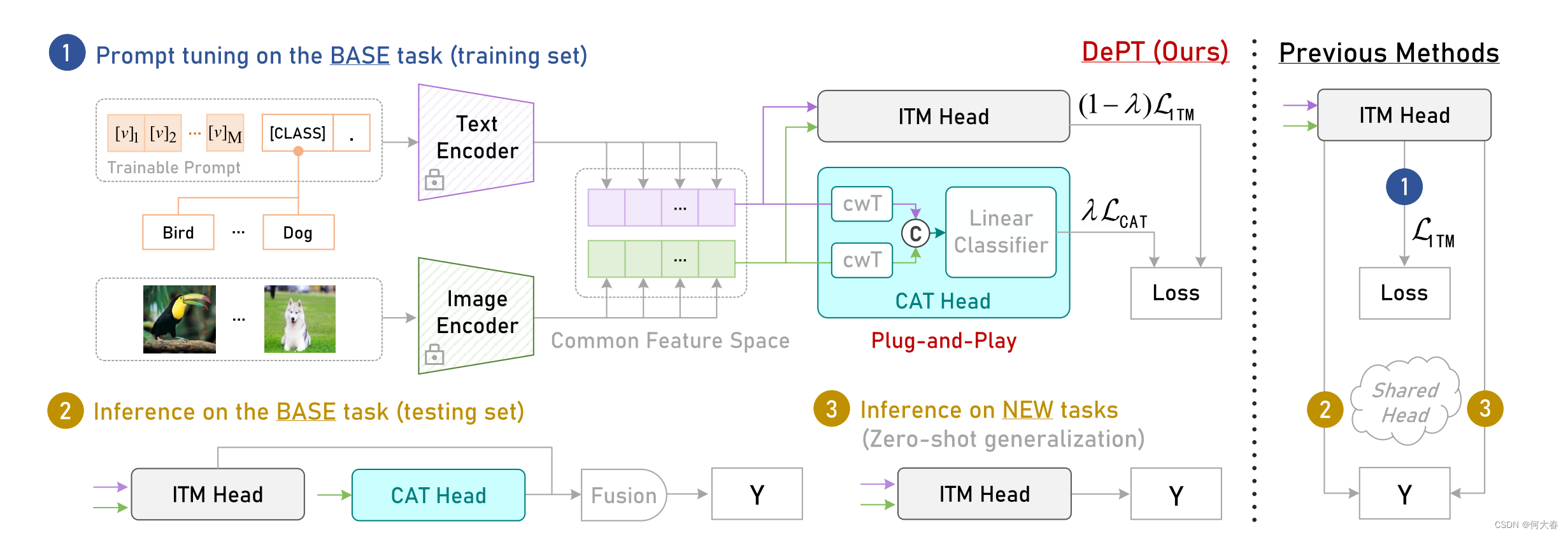
这项工作突破了提示调整中的基础-新任务权衡(BNT)困境,即调整后的模型对基础(或目标)任务的泛化效果越好,对新任务的泛化效果就越差,反之亦然。具体来说,通过对基础任务和新任务学到的特征进行深入分析,我们观察到BNT源于通道偏置问题 - 绝大多数特征通道被基础特定知识所占据,导致了对新任务重要的任务共享知识的崩溃。
在未来的研究中,我们可以进一步优化这些模型,比如调整模型的超参数、尝试更多的特征工程方法,或者结合多个模型的预测结果,以提高预测的准确性和可靠性。在对出租车出行数据进行了详细的探索性分析和异常数据检测后,我们进一步深入研究,尝试构建多种机器学习模型来对出租车的行程进行预测,以便更精准地把握出租车出行的规律,为城市交通规划和运营提供更有力的支持。从结果来看,不同的模型各有优劣。为了构建合适的机器学习
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达转载自:集智书童Image-Adaptive YOLO for Object Detection in Adverse ...
最近作者正在尝试部署多模态大语言模型llava,本文记录一下部署时遇到的问题。
初学python的同学,可能希望利用python搞一搞人脸识别。在这里,介绍一个比较简单的人脸识别的程序,python加上opencv进行人脸识别。工具:python3.10opencv4.5.4平台:win10vscode人脸识别程序:import cv2import cv2 as cvimport numpy as npdef face_detect(path):img=cv.imread(p
实验介绍此次实验帮助大家利用 OpenCV 去读取摄像头的视频流,你可以直接使用笔记本本身的摄像头,也可以用 USB 连接直接的摄像头。如果你在操作过程中,摄像头读取失败, 实验中还为你提供了几个问题排查步骤。当然,对视频进行操作时还需要讲解视频相关的编解码格式以及特定帧的读取。在实验的最后,还提供了 OpenCV 的项目实战:视频录制与视频读取。知识点视频录制视频编解码格式视频读取以及特定帧的读
FreeCAD是一种通用的参数化三维建模3D CAD软件。发展是完全开源(GPL的LGPL许可证)。FreeCAD直接的目的是在机械工程和产品设计,也适合在更广泛的用途,如建筑或其他工程专业,工程周围。FreeCAD具有类似CATIA,SolidWorks或Solid Edge的工具,因此也将提供CAX(CAD,CAM,CAE),PLM等功能。这将是一个基于参数化建模功能与模块化的软件架构,这使得
解决ValueError: y contains previously unseen labels: '103125'引发原因:有些标签训练集不存在,但却在测试集出现了,而且我们LabelEncoder使用的拟合fit是训练集的数据解决方式:把原数据集里面没有但是在新数据集遇到的新值放到一个类里面,再将类回传给LabelEncoder. 没有在训练集中出现的label,均视为"unknown"报错
在这篇文章中,作者将实体对齐建模为一个顺序决策任务,其中agent(智能体)根据实体的表征向量顺序地决定两个实体是匹配还是不匹配。所提出的端到端的基于强化学习(Reinforcement Learning, RL)的实体对齐(end-to-end RL-based entity alignment, RLEA)框架可以灵活地适应大多数给予嵌入的实体对齐方法。
X-ray铸件缺陷检测(YOLOV3网络)在暑假阶段老师给布置给我的实验任务是铸件的缺陷检测(x-ray)。我选择的网络是yolov3别人已经使用发展成熟的网络进行目标检测。我将本次实验分为数据集的处理+数据在yolov3网络下进行训练和验证。本次实验我参考的是GitHub中eriklindernoren的https://github.com/eriklindernoren/PyTorch-YOL
现象:我在跑transformer模型的时候,模型跑的很慢,而且可能第一次运行能跑一个batch然后卡了。第二次运行连第一个batch都没跑就卡了。尝试过程:看了模型和参数都是在GPU上,而且使用 top 命令也不是因为CPU占满。结果:发现罪魁祸首竟然是tqdm:换成模型就开始在GPU上欢快的运行起来啦...
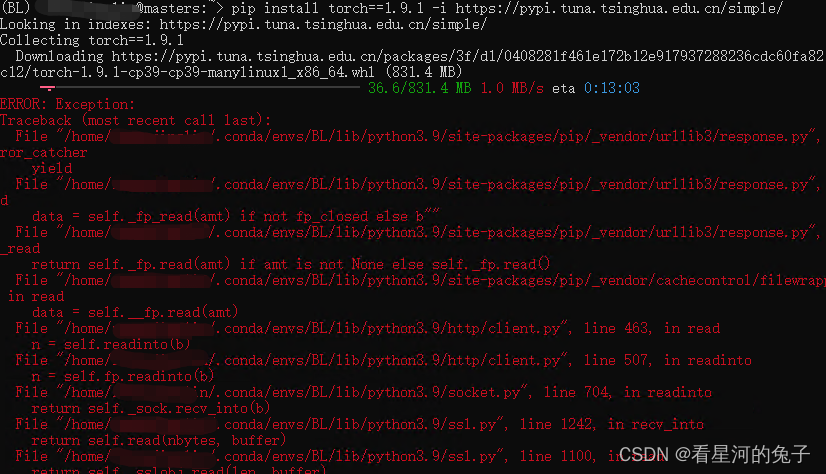
之前安装torch的时候可以很快成功,最近在服务器上安装torch的时候出现大面积报错如图所示:最后一句显示readtimeouterror。
我们看百科给的解释:很抽象,这也是数学的东西。百科这里,如果你对梯度理解了的话,这里就不抽象了。梯度下降法计算过程就是:沿着梯度下降的方向求解极小值,我们知道梯度是有方向的(对于多元函数来说),它是一个由偏导数组成的向量,这就相当于我们沿着该方向的逆方向移动。(常用于损失函数上)举个例子,倘若一个多元函数,有个参数x,其在该位置的梯度也就是偏导数为grad_X,我们设置的步长为Ir=0.01,那么
环境:win10、ubuntu通用目录1、下载代码2、创建虚拟环境3、安装环境4、验证安装是否成功1、下载代码https://codeload.github.com/open-mmlab/mmsegmentation/zip/master下载后,解压。将工程名文件夹名改为mmsegmentation,使用pycharm打开工程。2、创建虚拟环境step1、创建名为mmseg的conda虚拟环境,使
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.metrics import precision_recall_curve, average_precision_score'''y_true:类型:np.array; gt标签y_scores:类型:np.array; 由大至小排序的阈值score,'''#画曲线preci
准备连接 PostgreSQL 的 Label Studio 的 docker-compose.yml。(猜测依据)笔者看报错异常的源码时,app 标签和数据库的 model 名只由一个句点。,所以此时执行以下命令去除对应的表便导出成功了(笔者并没有系统学习过数据库)读者可参考修改,欢迎在评论区指出其能够变得更简洁、高效、可读的配置 👏。最后终端应该会打印类似如下信息,之后浏览器访问查看数据是否
ERROR: Could not find a version that satisfies the requirement keras-nightly (from versions: none)ERROR: No matching distribution found for keras-nightly 解决方案
位置编码的核心作用:帮助 Transformer 模型识别词语的顺序,避免无序问题。正弦和余弦的使用:提供平滑的、周期性的编码,适合捕捉相对位置关系。代码实现:通过简单的 PyTorch 代码构建位置编码并将其加到输入向量上。位置编码让 Transformer 能捕捉到句子中的顺序信息,是其能够成功应用于自然语言处理任务的关键。希望通过这篇文章,你能对位置编码的原理与实现有更清晰的理解!如果还有其
安装AimetTorch报错No matching distribution found for torch==1.9.0+cu111(torch和cuda版本均匹配)
对率回归闲来无事,学习了一下西瓜书线性回归模型,顺带做了下后边的题,其中对率回归是一种分类方法,西瓜书课后题3.3正好是一个二分类问题,先讲解下对率回归。其实对西瓜的二分类问题对率回归无非有三个参数,两个权重一个bias,参数量很小,主要目的就是训练这三个参数,有训练就要有目标函数,这里采用Logistic函数重新计算了一下权重偏差乘以西瓜属性后的0-1之间的值,以0.5为间隔区别好瓜坏瓜,很好理
安装Deep-Live-Cam过程中,我下载好了全部的requirements.txt里面的需要用到的第三方库,之后运行后成功出现以下界面,但是报错AttributeError: 'NoneType' object has no attribute 'shape'翻阅了原项目的issues发现了相同的问题,找到解决方法:选择图片时图片的路径中不能有中文字符,否则就会出现脸部被黑块覆盖。
A*B是矩阵(向量)对应元素相乘np.dot(A,B)是矩阵乘法A,B形式相同,各个元素相乘=B*AA,B满足矩阵相乘的条件。A为2x2,B为1x2,所以是A的每一行和B各元素对应相乘A为2x2,B为2x1,所以是A的每一列和B各元素对应相乘A为2x2,E为3x2,没办法使对应元素相乘F为1x1,对应元素相乘就直接用1*A的各个元素就可以...
dpmsolver 论文核心整理
'Clearsky DHI',和 'Clearsky DNI', 'Clearsky GHI'分别为是三个光伏电站的表示。数据属性: ‘Year’, 'Month', 'Day', 'Hour', 'Minute'这些是时间。),数据由威普罗有限公司(NYSE:WIT,BSE:507685,NSE:WIPRO)收集。开始位置(2009年1月1日0时0分开始开始)第一个光伏电站的测试集预测值与真实值
国税总局发票查验平台验证码最新获取方法,https://fpcy.guangdong.chinatax.gov.cn/NWebQuery/yzmQuery,JS逆向,国税验证码获取及识别方法。
的部分,CELU使用指数函数来确保梯度不会消失,有助于加速训练过程中的梯度流动。时,CELU函数退化为ReLU函数。是一个非负参数,用于控制。
Python读取csv文件并画出曲线图代码效果如图代码import pandas as pdimport matplotlib.pyplot as pltimport timeimport numpy as npplt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['font.family']='sans-serif'#...
语义信息:人脸提取出特征点后人脸就有了语义信息。高层语义特征:识别人脸的喜怒哀乐。现有问题:检测方法依赖于常见的后处理操作(如压缩)。想法来源:通过观察得,为了让伪造人脸的身份,语言和表情相匹配,大多数人脸视频伪造者会以某种方式操作嘴巴。例如:假嘴巴在发音某些音时无法充分闭合。口腔形状或口腔内部(例如牙齿)在帧与帧之间的变化。:在高度压缩泛化性好,能检测新的伪造方法。主要检测说话时的不协调。方法:
PIL、skimage、OpenCV中三次插值对比Python三种图像处理库,PIL、skimage、OpenCV中三次插值对比对比前的准备OpenCV插值(cubic)PIL插值(bicubic)Skimage插值(bicubic)总结Python三种图像处理库,PIL、skimage、OpenCV中三次插值对比
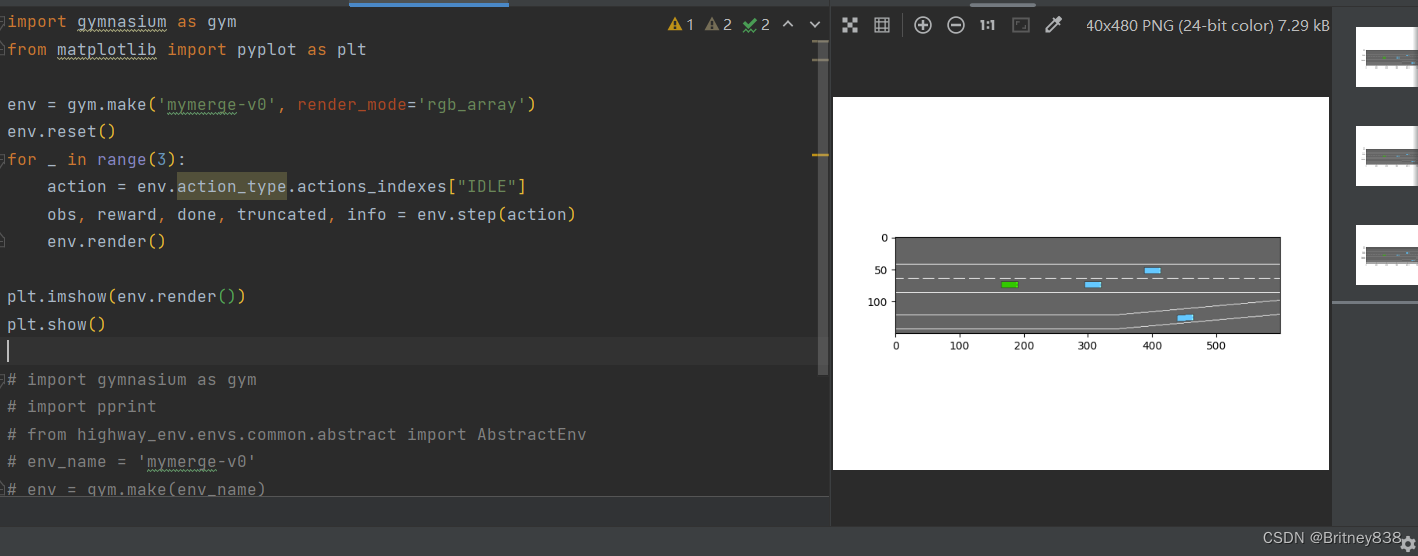
上一篇自定义自己的环境是基于highway-env=1.5的版本,是因为我在highway-env1.8.1的版本一直创建不成功,今天我解决啦!在highway-env文件夹下还有一个__init__.py文件,注意这里要区分不是上一步的__init__.py文件(即envs文件夹下的__init__.py文件),在该文件代码最后添加。5、在原来的envs文件夹中有一个__init__.py文件,
anaconda安装好之后,有个默认的环境base,可以在anaconda powershell prompt中输入指令conda info -e进行查看,安装新的虚拟环境操作如下。(1)在C盘users文件夹下找到.conda文件夹,并把这个.conda文件夹移到自己想要存放的位置,然后删除C盘的.conda文件夹。其中,mlpy这个库需要本地安装,先下载mlpy轮子文件,然后在mlpy所在的文
原因是我的文件名和包名一样了,修改下python的文件名即可。
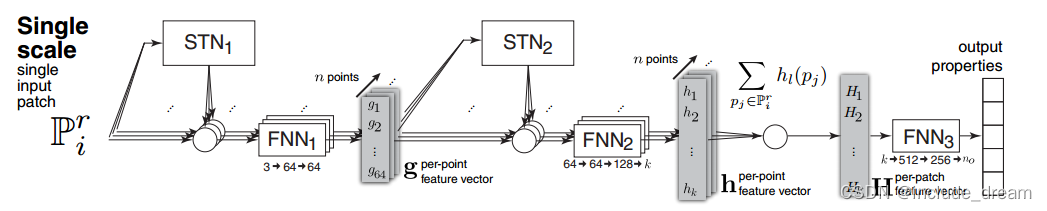
AbstractIn this paper, we propose PCPNET, a deep-learning based approach for estimating local 3D shape properties in point clouds.In contrast to the majority of prior techniques that concentrate on gl
中文维基百科中没有关于log probability的词条,故将英文维基机翻之后上传至此。原文链接https://en.wikipedia.org/...
最近几天重新复习了有关信息编码的知识,首先跟大家推荐两本书吧。《数字通信原理与技术》(北京邮电出版社的)《ldpc原理与应用》首先先搞清几个概念。1.什么是分组码?每个码组的监督码元仅与该码组的信息码元有关,而与其他码组的信息码元无关,这类码称为分组码。在分组码中,监督码元仅监督本码组中的信息码元。编码效率R=k/n,k是信息位,n-k是监督位,R越大,信息位所占的比重越大...
import matplotlib.pyplot as pltimport numpy as npx=range(1,41)values=np.random.uniform(size=40)my_dpi=96plt.figure(figsize=(480/my_dpi, 480/my_dpi), dpi=my_dpi)plt.stem(x, values)plt.ylim(0, 1.2)plt.s
python
——python
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net




 天启AI社区
天启AI社区

 2048 AI社区
2048 AI社区