登录社区云,与社区用户共同成长
邀请您加入社区
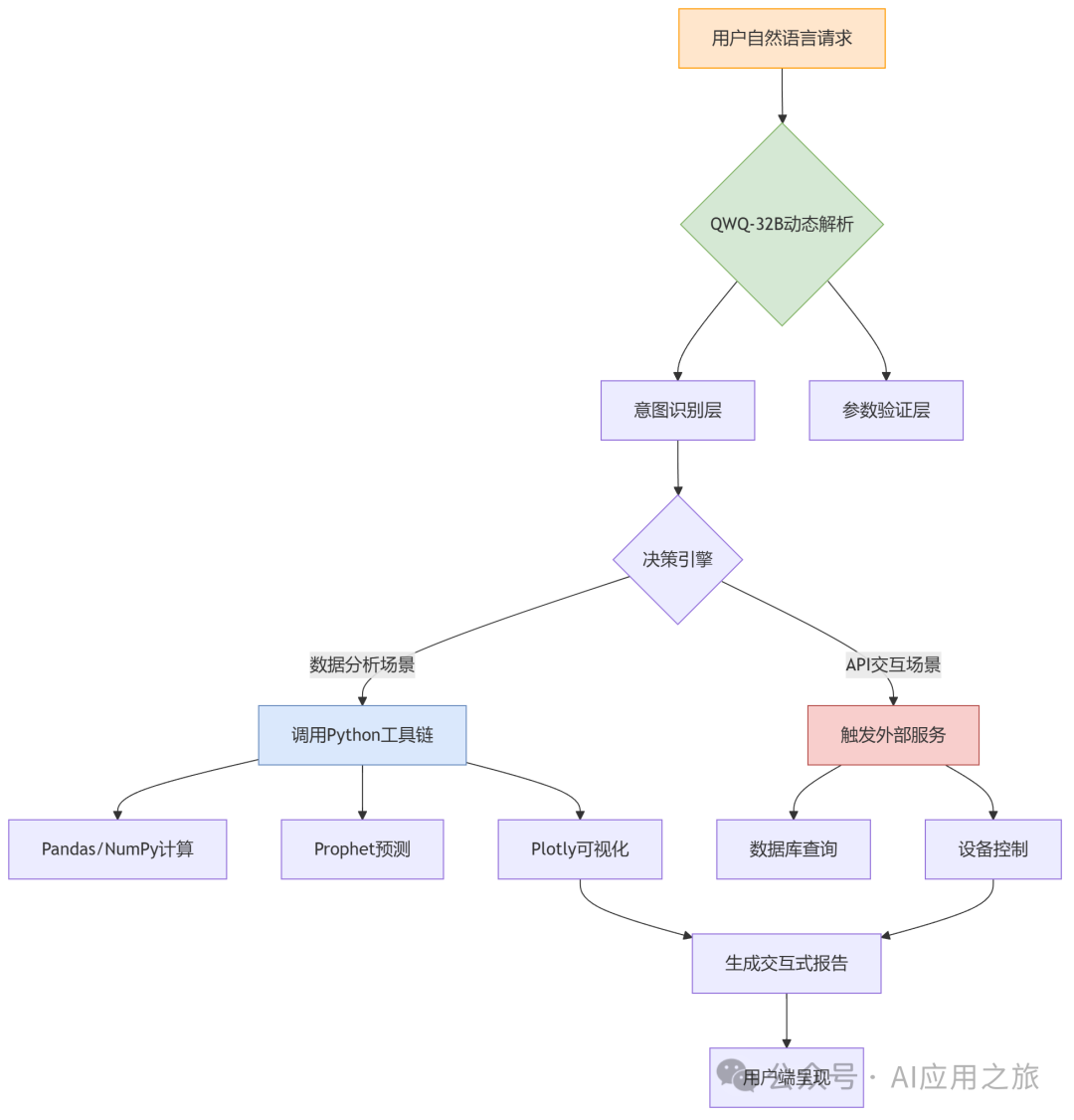
1️⃣:突破训练数据时效限制,实时调用外部知识(如调用Wind金融终端获取最新财报)2️⃣:通过API控制物联网设备(案例:某工厂部署后设备故障响应速度提升23倍)3️⃣:实现「思考-执行-验证」的闭环推理(实测复杂任务完成率从37%→89%):当大模型可主动调用10万+工具时,传统SaaS软件架构将彻底重构!某电商巨头采用QWQ-32B实现:✅:用户问“为什么东北区销量下滑” → 自动调用SQL
我们就简单举一个例子把star_rating为3到4中的positive减去0.25把star_rating小于3的positive减去0.3star_ratingpositive050.98072110.737101250.945672320.729632450.99853530.408589610.65...
大模型分为浅层次、中层次、高层次应用方向,未来无限可能,尽在思考演练中。
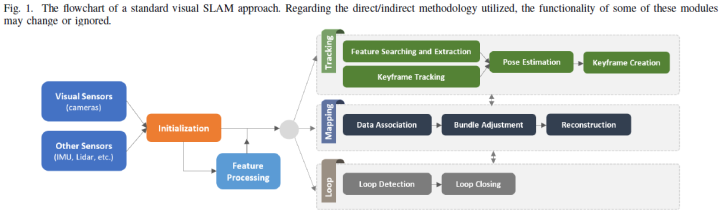
近年来,基于视觉的传感器在SLAM系统中显示出显著的性能、精度和效率提升。在这方面,视觉SLAM(VSLAM)方法是指使用相机进行姿态估计和地图生成的SLAM方法。许多研究工作表明,VSLAM优于传统方法,传统方法仅依赖于特定传感器,例如激光雷达,即使成本较低。VSLAM利用不同的摄像机类型(例如单目、双目和RGB-D),在不同的数据集(例如KITTI、TUM RGB-D和EuRoC)和不同的环境
丨目录: · 概述 · 业界方案 · 本文方法 · 实验部分 · 总结 ·参考文献1. 概述在以淘宝搜索广告为代表的经典搜推广场景中,转化率(CVR)预估作为面向GMV优化的重要基础能力发挥着不可替代的重要作用。特别地,在广告场景中,CVR预估同时作为排序机制与CPC、oCPX等多种出价策略的基础模块,承担着平台效率与广告主ROI兼顾、保持电商广...
计算机毕业设计Python流量检测可视化 DDos攻击流量检测与可视化分析 SDN web渗透测试系统 网络安全 信息安全 大数据毕业设计
双语评估替换分数(简称BLEU)是一种对生成语句进行评估的指标。完美匹配的得分为1.0,而完全不匹配则得分为0.0。这种评分标准是为了评估自动机器翻译系统的预测结果而开发的,具备了以下一些优点:计算速度快,计算成本低。容易理解。与具体语言无关。已被广泛采用。BLEU评分是由Kishore Papineni等人在他们2002年的论文BLEU a Method for Automati...
导读协同过滤:在推荐领域中,让人耳熟能详、影响最大、应用最广泛的模型莫过于协同过滤。2003年,Amazon发表的论文[1]让协同过滤成为今后很长时间的研究热点和业界主流的推荐模型。什么...
病害影响植物微生物组群落构建与功能适应Disease-induced changes in plant microbiome assembly and functional adaptat...
Help panel font size指的是RStudio帮助面板中字体的大小,用于显示帮助文档、函数说明等信息。上图设置为12。调整方法如下:打开RStudio,进入“Global Options” > “Appearance”,在“Help panel font size”部分选择所需的字体大小。调整帮助面板中的字体大小可以使文档内容更易读,适合不同的屏幕尺寸和用户需求。
每天给你送来NLP技术干货!来自:复旦DISC引言TreeBank 作为自然语言语法的结构化表示可谓广为人知,其实在语义层面也有一种类似的结构化方法——抽象语义表示(Abstract Meaning Representation,AMR)。它能记录自然语言文本中最重要的语义信息,但并不限制实际表达时的语法结构。本次分享我们将向读者介绍 ACL 2022 中与 AMR 有关的三篇论文,一窥 AMR
1. 文章信息文章题目为《Improved Mask R-CNN for obstacle detection of rail transit》,是2022年发表在Measurement上...
XGBoost的重要剪枝参数与波士顿房价数据集调参实战
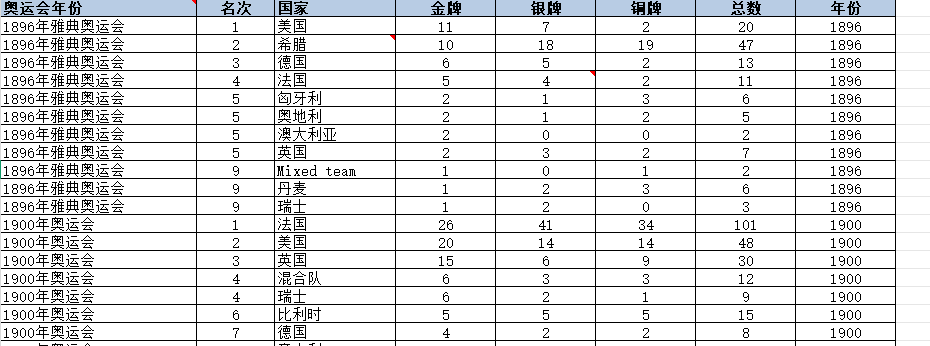
自1896年首届现代奥运会至2024年巴黎奥运会的完整奖牌统计信息,涵盖128年的体育竞技历史。3. **政策制定**:如德国奖牌数下降趋势(1984年108枚至2024年33枚)反映其体育战略调整需求;2. **社会经济**:通过奖牌分布与国家GDP、人口数据的相关性,探讨体育投入与产出的经济学模型;1. **体育科学**:可量化分析各国优势项目,如中国跳水(47金)、举重(38金)的长期竞争力
框架分为三个主要部分:种子Alpha工厂、多智能体决策制定和权重优化方法。初始阶段使用大型语言模型(LLM)过滤和分类多模态文档,构建种子Alpha工厂。LLM处理大量和多样化数据集的能力确保了种子alpha集合全面且强大,按照金融alpha挖掘研究建立的独立alpha类别进行分类。第二阶段,框架采用多模态多智能体决策过程。这种多智能体方法允许结合不同的风险视角,增强策略在不同市场条件下的适应性和
近年来,自动驾驶、元宇宙、人工智能等应用不断创新发展,数据规模、算法复杂度 以及算力需求爆发式增长。各类加速处理器已成为算力基础设施的重要组件,基于 CPU+xPU 的异构计算系统逐渐成为各算力场景的主流架构。然而,随着异构计算系统的种 类和数量越来越多,xPU 性能与灵活性难以兼顾、各 xPU 间计算孤岛问题难以协同、调试 和维护成本增高等问题愈发凸显,亟需从异构融合计算方向加强理论研究和实践探
分享一下我的整体思路。我觉得方法都是次要的,因为每个人的需求、情况都不同——唯有思路可以借鉴。出发点和对应解法:第一,信息过载,无法逐一细细消化。所以需要AI辅助,通过总结、提炼等方式帮助我们先快速、大致掌握。第二,人脑不适合用来记东西,而应该用来做创造性的工作。所以需要“第二大脑 / Second Brain”来存储,需要AI根据语义进行检索(所有工具都有关键词检索,再加上语义检索就齐全了)。第
今天我们来谈论一下pandas库当中文本数据的操作,希望大家再看完本篇文章之后会有不少的收获,我们大致会讲创建一个包含文本数据的DataFrame常用处理文本数据的方法的总结正则表达式与D...
通过对历史交通事故数据的分析,结合实时交通数据,预测潜在的交通事故风险,并向相关部门和驾驶者提供预警信息。:利用机器学习和人工智能算法,如神经网络、支持向量机等,对交通数据进行训练和学习,建立交通流量预测、事故预警等模型,实现对高速公路运行状态的精准预测。:通过收集高速公路的实时交通数据、历史数据、气象数据等,利用大数据分析和挖掘技术,提取出有价值的交通信息,为预测仿真提供数据支持。:通过物联网和
基因组水平的宏基因组学揭示了铁代谢在干旱诱导的根际微生物组动态中的作用Genome-resolved metagenomics reveals role of iron metabolis...
多模态分类研究随着卫星图像、生物识别和医学等领域的新数据集越来越受欢迎.
GraphRAG是一种结构化的分层 RAG 方法,与依赖纯文本片段或简单文本分块的简单方法形成鲜明对比。该过程包括从原始文本中提取知识图谱、构建社区层次结构、为这些社区生成摘要,并在执行基于 RAG 的任务时利用这些结构。wp:heading。
来自|新智元【导读】每次GAN模型都要从头训练的日子过去了!最近CMU联手Adobe提出了一种新的模型集成策略,让GAN模型也能用上预训练,成功解决「判别器过拟合」这个老大难问题。进入预训练时代后,视觉识别模型的性能得到飞速发展,但图像生成类的模型,比如生成对抗网络GAN似乎掉队了。通常GAN的训练都是以无监督的方式从头开始训练,费时费力不说,大型预训练通过大数据学习到的...
OCR(Optical Character Recognition),即光学字符识别,是一种利用计算机自动识别和解析图像中的文字信息的技术。
NV-Embed-v2 是由 NVIDIA 開發的一個通用嵌入模型,於 2024 年 8 月 30 日在 Massive Text Embedding Benchmark (MTEB) 上排名第一,得分為 72.31,涵蓋 56 個文本嵌入任務。它特別在檢索子類別中表現出色,得分為 62.65,涵蓋 15 個任務,這對檢索增強生成(RAG)技術的發展至關重要。該模型基於 Mistral-7B-v0
拉曼光谱的概念不同的入射光频率的散射光谱进行分析所得到的分子振动、转动的信息,并应用于分子结构分析研究的一种分析方法,称为拉曼光谱(Ramanspectra)。拉曼光谱的特征拉曼散射谱线的波数虽然随入射光的波数而不同,但对同一样品,同一拉曼谱线的位移与入射光的波长无关,只和样品的振动转动能级有关。在以波数为变量的拉曼光谱图上,斯托克斯线和反斯托...
汇编内容分为七个部分,包括综合数据、各地区粮食和油料、棉烟糖料、蚕茧水果、肉禽蛋奶、蔬菜以及畜产品的成本和收益数据。特别指出的是,全国性数据中并未包含香港、澳门特别行政区和台湾省的数据。在具体数据方面,“三种粮食平均”指的是稻谷、小麦、玉米的平均成本和收益;此外,对于“规模生猪”、“规模肉鸡”、“规模蛋鸡”、“规模奶牛”,汇编中提供了不同规模(小规模、中规模和大规模)的平均数据。蔬菜的平均成本和收
SPANN:十亿规模的高效近似最近邻搜索
今天分享一下如何在GEE中计算整年影像的可用数量。在阅读文献的过程中,发现在使用GEE处理影像时,都会说明某年到某年有多少景影像,处理了多少景。我也想知道在自己的研究区里有多少景可用的影像以宁夏为例GEE代码如下:var roi = ee.FeatureCollection("users/guaicai666666/Ningxia");var l8_sr = ee.Im...
1 TransModeler的前世今生TransModeler的研发思路最早发轫于1993年MITSimLab时期,它的诞生和杨齐博士以及Caliper公司密不可分。杨齐博士1991年进入...
Pony模型是一场AI大模型的革命,让Stable Diffusion世界变得五彩斑斓。如今,80%的新增大模型都是以Pony为底模进行创作。但Pony系列的缺点也显而易见:打分机制非常繁琐。如果不使用打分,出图效果比较差。虽然之前我推荐了免打分的二创模型,但出图效果在不打分的情况下,达不到最优,只是勉强可看。今天给大家推荐一组Embedding模型,体积小,名字短,好记忆,可以方便的取代打分机制
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达转载自:集智书童SepViT: Separable Vision Transformer论文:https://arxiv.org/abs/2203.15380Vision Transformers在一系列的视觉任务中取得了巨大的成功。然而,它们通常都需要大量的计算来实现高性能,这在部署在资源有限的设备上这...
文章信息《Traffic flow optimization: A reinforcement learning approach》是2016年发表在Engineering Applications of Artificial Intelligence上的一篇文章。摘要交通拥堵会造成诸如延误、燃料消耗增加和额外污染等重要问题。本文提出了一种基于强化学习的交通流优化方法。我们表明交通流优化问题可以
对于程序员转行方向的推荐,可以基于当前的技术趋势、市场需求以及程序员的个人技能和兴趣来综合考虑。
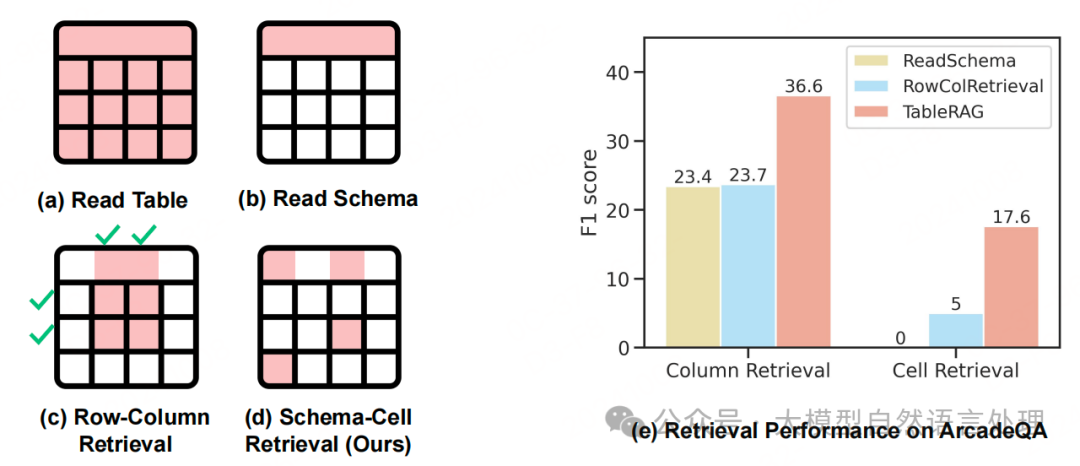
前面很多期介绍了密集文档场景的RAG方法,今天来看看大量表格场景的RAG怎么做的。现有结合大模型的方法通常需要将整个表格作为输入,这会导致一些挑战,比如位置偏差、上下文长度限制等,尤其是在处理大型表格时。为了解决这些问题,文章提出了TableRAG框架,该框架利用和,以在。这种方法能够更高效地编码数据和精确检索,显著减少提示长度并减轻信息丢失。表提示技术在LLM中的应用比较语言模型读取整个表格。这
它不仅关注经济效益,还强调环境效益,体现了绿色发展理念。在测算过程中,劳动投入以企业员工数作为代理变量,资本投入以企业固定资产净额作为代理变量,能源投入则以企业所在城市工业用电量按企业从业人员占城市城镇人员就业比重进行换算作为代理变量。期望产出以企业营业收入作为代理变量,而非期望产出则以企业从业人员占所在城市城镇人员就业比重对“工业三废”即工业二氧化硫、工业废水、工业烟粉尘排放量进行换算,作为企业
本文其实从去年就开始酝酿,一直没动手写。没想到PET map相关的研究发展迅速,马上就要和AHBA的基因表达分析一样烂大街了。本文简单梳理了关于PET map最近的一些应用和进展,这些资源...
大数据文摘出品整理:牛婉杨12月1日,GTIC 2020 AI芯片创新峰会在京举办,本次峰会聚集了AI芯片以及各个细分赛道的产、学、研精英人士,共议AI芯片在中国半导体黄金时代的创新与未...
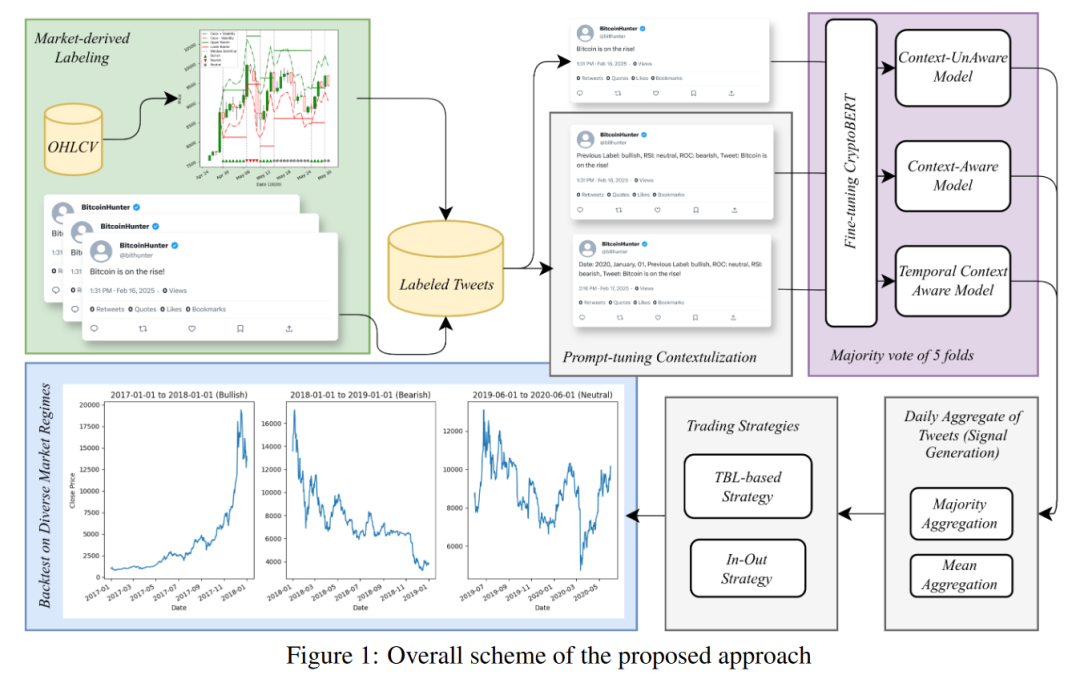
在当今数字化时代,社交媒体平台上的信息传播速度极快,影响力也日益增强。一条来自公众人物的推文就可能在几分钟内引发全球市场数十亿美元的资金流动。随着市场的发展,投资者群体的心理和行为对市场走势的影响愈发显著。投资者情绪通常反映在推特等社交媒体平台上,成为市场预期的代理指标。金融情感分析(FSA)旨在量化这些情绪,并将其分类为看涨(Bullish)、看跌(Bearish)或中性(Neutral),以预
采样策略汇总背景数据采样很多人都听过,书上亦或是博客上面,但并不是每个人在实践中都会用到,按实践经验来讲,原始数据包含了所有的信息,我们随意增加数据亦或者是删除数据,完全是没有必要的操作...
根据相关统计数据,2010年,上市公司研发支出总额约为560亿元,2011年增至995亿元,2012年为1313亿元,2013年为1516亿元,2014年为1725亿元,2015年为2279亿元,2016年为2808亿元,2017年为3257亿元,2018年为3589亿元,2019年为4000亿元,2020年为4500亿元,2021年为5000亿元。在研发人员数量方面,2021年,行业研发人员总数
本周对南宁伶俐工业园区污水处理厂进行调研,了解了该污水处理厂的详细工艺。又基于UCI水处理数据集,使用深度学习方法构建了预测模型,对水处理单元的进出水水质进行预测分析。数据预处理包括数据清洗、PCA降维、滑动窗口数据增强等,以提升模型的计算效率和准确性。模型采用卷积神经网络(CNN)、长短期记忆网络(LSTM)及注意力机制结合的CLATT模型,通过多层卷积、LSTM层、多头注意力机制及残差块提取特
vlc视频A video’s bitrate is a key piece of information in determiningthe quality of said video.Even if two videos have the same resolution, a lower bitrate is going to result inless detail and clarit...
点击上方“3D视觉工坊”,选择“星标”干货第一时间送达作者丨WinstonDeng@知乎(已授权)来源丨https://zhuanlan.zhihu.com/p/345201439编辑丨极...
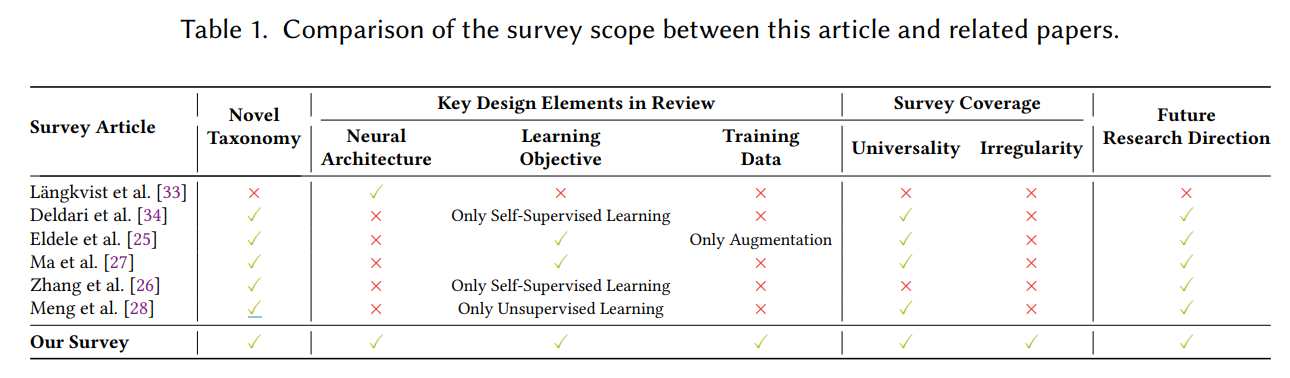
时间序列数据存在于现实世界系统和服务的每一个角落,从天空中的卫星到人体上的可穿戴设备。通过提取和推断这些时间序列中的有价值信息来学习表示,对于理解特定现象的复杂动态并做出明智的决策至关重要。有了学习到的表示,我们可以更有效地进行许多下游分析。在几种方法中,深度学习在从时间序列数据中提取隐藏模式和特征方面展现了卓越的性能,而无需手动特征工程。本文首先基于三个设计最先进的通用时间序列表示学习方法的基本
大数据
——大数据
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net




 2048 AI社区
2048 AI社区