登录社区云,与社区用户共同成长
邀请您加入社区
共享单车之租赁需求预估第2关:特征工程
本地的/home/hadoop/hadoop-2.7.7 文件夹复制到另一条服务器下的/home/hadoop/ 下。如下命令不会覆盖目标地址的同名文件夹sc...
报错操作本地文件,读取后存储到数据库中的时候报错,明显是数组下标越界,所以基本可以确认是在拆分的时候分隔符可能搞错了。但仔细一想,不对,前50条数据拆分后是可以的,那应该是第51行数据出现了问题。使用notepad++打开数据集后,果然发现了端倪。第51行数据集中间的一个分隔符发生了改变。所以我干脆将所有的分隔符换成了,...
Mapreduce实现机器学习
需求二: 上行流量倒序排序(递减排序)分析,以需求一的输出数据作为排序的输入数据,自定义FlowBean,以FlowBean为map输 出的key,以手机号作为Map输出的value,因为MapReduce程序会对Map阶段输出的key 进行排序Step 1: 定义FlowBean实现WritableComparable实现比较排序Java 的 compareTo 方法说明:compar...
http://t.csdnimg.cn/OySPS
注:参考林子雨老师教程,具体请见MapReduce编程实践(Hadoop3.1.3)_厦大数据库实验室博客一.实验目的1.理解Hadoop中MapReduce模块的处理逻辑。2.熟悉MapReduce编程。二.实验内容1.新建文件夹input,并在其中创建三个指定文件名的文本文件,并将特定内容存入三个文本。2.启动Hadoop伪分布/全分布模式式,将input文件夹上传到HDFS上。3.编写Map
MapReduce是一个 分布式运算程序 的编程框架,是用户开发“基于 Hadoop的数据分析应用”的核心框架。MapReduce核心功能是将 用户编写的业务逻辑代码 和 自带默认组件 整合成一个完整的分布式运算程序 ,并发运行在一个 Hadoop集群上。
今天大数据比赛结束了,放在百度网盘中,给大家做一下参考提取码adsahttp://2021年安徽省大数据与人工智能应用竞赛 大数据-本科组赛题
⭐ ⭐ ⭐ ⭐ ⭐ 博主信息⭐ ⭐ ⭐ ⭐ ⭐博主名称:Yuan-Programmer链接直达:https://bbs.csdn.net/topics/603957283链接直达:https://bbs.csdn.net/topics/603957283链接直达:https://bbs.csdn.net/topics/603957283链接直达:https://bbs.csdn.net/topic
若为出现预期结果, 可私信我答疑。
文章目录1.判断作业状态是否为DEFINE后,调用submit方法 1.1 再次确认作业状态,使用新api 1.2 创建连接(不同执行模式,创建不同的runner) 1.3 获取提交器对象 1.4 提交器对象提交作业(生成切片规划文件和配置文件) 1.5 修改状态为RUNNING2.verbose设置为true时,监控和打印job信息提交作业入口boolean b = job.waitF
文档(Document):一般搜索引擎的处理对象是互联网网页,而文档这个概念要更宽泛些,代表以文本形式存在的存储对象,相比网页来说,涵盖更多种形式,比如Word,PDF,html,XML等不同格式的文件都可以称之为文档。Map操作的每一行,对所有出链发射当前网页概率值的1/k,k是当前网页的出链数,比如对第一行输出<B,1/31/4>,<C,1/3*1/4>,<D,1/3*1/4>;以第一行为例:
2005,01,01,16,-6,-28,10157,260,31,卷云,0,-9999。根据提示,在右侧编辑器补充代码,对数据按照一定规则进行清洗。本关任务:对数据按照一定规则进行清洗。运行比较耗时,所以评测时间较长,大概在。命令行输入:start-all.sh。具体本关的预期输出请查看右侧测试集。因为大数据实训消耗资源较大,且。评测之前先在命令行启动。秒左右,请耐心等待。
介绍如何在Intellij Idea中通过创建maven工程配置MapReduce的编程环境。
因为大数据实训消耗资源较大,且map/reduce运行比较耗时,所以评测时间较长,大概在60秒左右,请耐心等待。评测之前先在命令行启动hadoop:start-all.sh;点击测评后MySQL所需的数据库和表会自动创建好。在该箭头所指的位置进行代码文件的切换。具体本关的预期输出请查看右侧测试集。LogMR:MapReduce操作。DBHelper:MySQL工具类。之后在命令行启动hadoop。
求和是 MapReduce 中最常见的数值算法,使用 Map 端读取数据,若只需要针对单行数据进行求和的话,只 Map 端就可以满足了。若需要针对多行数据进行分组求和的话,那就需要 Map 端和 Reducer 端相结合,以 key 值区分来将所有数值进行求和,达到分组求和的效果。
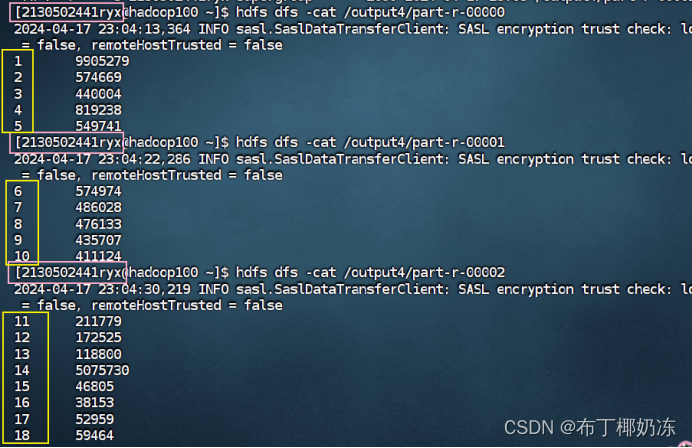
一、MapReduce 示例程序的导入并运行测试二、准备 4 个小文件(文件大小分别为 1.7M,5.1M,3.4M,6.8M)1. 第一种情况,默认分片:不修改程序代码,直接使用 WordCount 源程序2. 第二种情况,在代码中增加如下内容3. 第三种情况,将数值设为 20M三、对 sogou.500w.utf8 数据进行分析,使用 MapReduce 编写程序完成。1.程序源代码2. 程序
通过以上步骤,你就可以完成 HBase 的基本安装、配置以及常见的基本操作。HBase 的灵活性和高性能特性使其适合处理大规模数据,同时提供了多样的查询和管理能力。HBase 依赖于 Hadoop,因此首先确保 Hadoop 已经正确安装和配置。如果没有安装,请先下载并安装 Hadoop。:如果遇到连接或启动失败的情况,检查 Hadoop 和 Zookeeper 是否正常运行。下载 HBase 最
其实这一篇我有简单提到这个MapReduse的概念,但是只是粗略的讲解,可以去大致看一眼MapReduse跟HDFS、YARN的关系:(另外注意,这一篇文章需要有一定java基础,本文大量用到java,不再过多解释java原理)
若未出现预期结果可私信我答疑。若操作不明白可私信我。
设置Map,reduce参数调优其个数,以及如何保证输出端的小文件合并等问题
来源:Hack电子该FPGA项目旨在详细展示如何使用Verilog处理图像,从Verilog中读取输入位图图像(.bmp),处理并将处理结果写入Verilog中的输出位图图像。提供了用于读...
作者新手小白,仅为学习&交流2020年3月26日22:12:29开发环境OS: Win10Hadoop版本: hadoop-3.1.2IDE: Intelij IDEA 2019.3.3Hadoop Path: E:\Hadoop\Hadoop\hadoop-3.1.2\hadoop-3.1.2Win本地安装hadoop1.讲搭建hadoop平台时的.tar.gz文件直接解...
背景 MediaCodec 作为Android自带的视频编解码工具,可以直接利用底层硬件编解码能力,现在已经逐渐成为主流了。API21已经支持NDK方法了,MediaCodec api设...
Hive时间函数总结获取当前时间0: jdbc:hive2://linux01:10000> select current_date;+-------------+|_c0|+-------------+| 2020-09-14|+-------------+获取当前时间戳0: jdbc:hive2://linux01:10000> select ...
import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop
MIT 6.824 分布式系统 2020春季课程 Lab1 MapReduce实现思路
Hadoop 是一个开源的分布式计算和存储框架,它的作用非常简单,就是在多计算机集群环境中营造一个统一而稳定的存储和计算环境,并能为其他分布式应用服务提供平台支持,相当于在某种程度上将多台计算机组织成了一台计算机。Hadoop 框架最根本的原理就是利用大量的计算机同时运算来加快大量数据的处理速度。Hadoop 集群可运行于一般的商用服务器上,具有高容错、高可靠性、高扩展性等特点。适合一次写入,多次
最近在重新学习MapReduce框架,为之后学习Spark计算框架打下基础;想到之前实现过一个WordCount,借着大数据技术这门课的机会,在此项目中实现TopN中文词频统计。划重点!由于三个实验难度层层递进,故本文只对MapReduce实现TopN中文词频统计做重点阐述。但是后续会把三个项目的实现都打包发上来,感兴趣的家人可以自行下载参考。
1.背景介绍1. 背景介绍HBase是一个分布式、可扩展、高性能的列式存储系统,基于Google的Bigtable设计。它是Hadoop生态系统的一部分,可以与Hadoop Distributed File System(HDFS)和MapReduce等组件集成。HBase的核心特点是提供低延迟、高可靠性的数据存储和访问,适用于实时数据处理和分析场景。在大数据时代,数据的规模不断增长,...
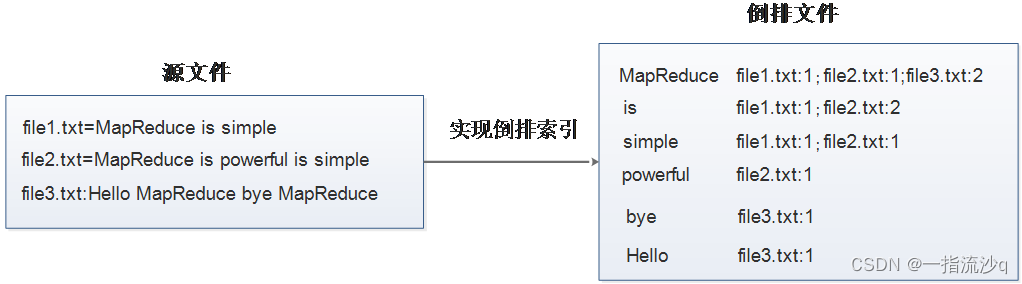
目录一、问题介绍(一)案例分析1. 倒排索引介绍2. 案例需求及分析(二)案例实现 1.Map阶段实现2.Combine阶段实现3.Reduce阶段实现4.Driver程序主类实现5.效果测试二、完整代码 三、运行结果倒排索引是文档检索系统中最常用的数据结构,被广泛应用于全文搜索引擎。倒排索引主要用来存储某个单词(或词组)在一组文档中的存储位置的映射,提供了可以根据内容来查找文档的方式,而不是根据
order by的使用及讲解1. order by的使用大家都清楚在hive中order by是用来排序的,使用语法如下SELECT * FROM tab_name ORDER BY column_name;在使用order by的时候默认是按照升序进行排序的(ASC),字符串类型就是按照字典顺序进行排序的,数值类型就是按照数值的大小进行排序的具体列子如下:表中数据:goodsgtypeprice
hadoop–MapReduce倒排索引1.倒排索引介绍倒排索引是文档检索系统中最常用的数据结构,被广泛应用于全文搜索引擎。倒排索引主要用来存储某个单词(或词组)在一组文档中的存储位置的映射,提供了可以根据内容来查找文档的方式,而不是根据文档来确定内容,因此称为倒排索引(Inverted Index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(Inverted File)。2.案例需求
1. MapReduce1.1 MapReduce 是什么MapReduce:是 Hadoop 中的一个分布式计算框架,基于 MapReduce 写出的应用程序能够运行在大型集群上,并以一种可靠容错的方式并行处理上 T 级别的数据集。一个 MapReduce 作业(Job)通常会把输入的数据切分为若干个独立的数据块,由 Map 任务(Task)以完全并行的方式处理它们。框架会对 Map 的输出先进
mapreduce
——mapreduce
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net




 2048 AI社区
2048 AI社区

 MCP技术社区
MCP技术社区

 AI编程社区
AI编程社区


 永洪数据分析社区
永洪数据分析社区






 讯飞AI开发者社区
讯飞AI开发者社区




 脑启社区
脑启社区


















 魔乐社区
魔乐社区