登录社区云,与社区用户共同成长
邀请您加入社区
当数据的样本数比特征数还少时候,矩阵的逆不能直接计算。即便当样本数比特征数多时,的逆仍有可能无法直接计算,这是因为特征有可能高度相关。这时可以考虑使用岭回归,因为当的逆不能计算时,它仍保证能求得回归参数。岭回归是缩减法的一种,相当于对回归系数的大小施加了限制。另一种很好的缩减法是lasso。Lasso难以求解,但可以使用计算简便的逐步线性回归方法来求得近似结果。缩减法还可以看做是对一个模型增加偏差
实用性完整性真实性艺术性交互性。
理解高阶损失函数在深度学习可解释性方面的应用(原论文名:Understanding Impacts of High-Order Loss Approximations and Featuresin Deep Learning Interpretation)作者:Sahil Singla,Eric Wallace,Shi Feng,Soheil Feizi论文下载地址:https://arxiv.o
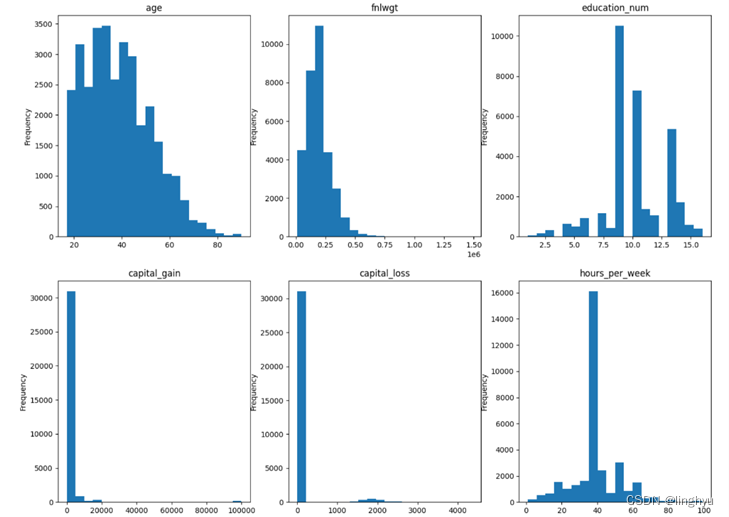
对1994年美国人口普查数据库进行分类预测与集成学习的实验。通过数据探查、清洗和预处理,构建了用于预测个人年收入是否超过50等任务的分类模型。通过探索数据结构、处理缺失值、转换文本字段为数值类型以及优化模型参数等步骤,成功训练了XGBoost模型,并实现了特定场景下任务的分类预测。
它由确定前沿目标的确定性部分、确定双边误差项的随机部分和确定与随机前沿距离的单边无效误差项组成,可用于研究不同行业的生产、成本、收入、利润等目标,在教育、金融市场、房地产、交通等领域得到了广泛运用。其中,“lny lnk lnl tlhat” 是被解释变量和解释变量,“frontier (truncnormal)” 表示技术无效率项服从截断正态分布,“ineff (m = z*delta)表示技术
1.背景介绍线性判别分析(Linear Discriminant Analysis, LDA)和支持向量机(Support Vector Machine, SVM)都是用于分类和回归的强大工具,它们在机器学习和数据挖掘领域具有广泛的应用。在本文中,我们将深入探讨这两种方法的核心概念、算法原理以及实际应用。线性判别分析(LDA)是一种假设测试方法,它假设两个或多个类别的数据是来自不同的高斯分...
43_Pandas版本的检查(pd.show_versions)有以下几种方法可以检查脚本中使用的Pandas的版本。获取版本号:__version__属性显示诸如依赖包之类的详细信息:show_versions()函数获取版本号:__version__属性像许多其他软件包一样,Pandas也可以使用__version__属性获取版本号。import pandas as pdprint(pd.__
本章详细介绍了数据缺失的原因、影响及处理方式、数据归一化处理的方法等内容。缺失值定义百度百科:缺失值是指粗糙数据中由于缺少信息而造成的数据的聚类、分组、删失或截断。它指的是现有数据集中某个或某些属性的值是不完全的。简单来说就是:部分数据缺失了缺失值产生原因无意的:信息被遗漏,比如由于工作人员的疏忽忘记而缺失;或由于数据采集器故障等原因造成的缺失,比如系统实时性要求较高的时候,机器来不及判和决策而造
文章目录一、Cosine Similarity是什么?二、L2distance是什么?三、Cosine Similarity 与L2distance的区别总结一、Cosine Similarity是什么?余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。计算公式如下:二、L2distance是什么?L2
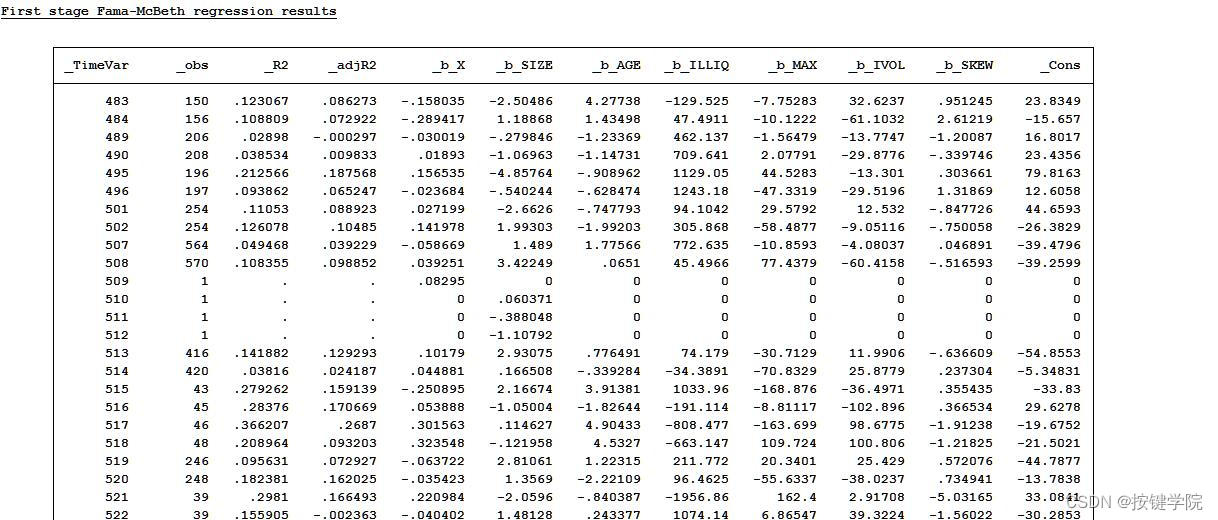
Fama-Macbeth两步回归代码.do。Fama-Macbeth两步回归。
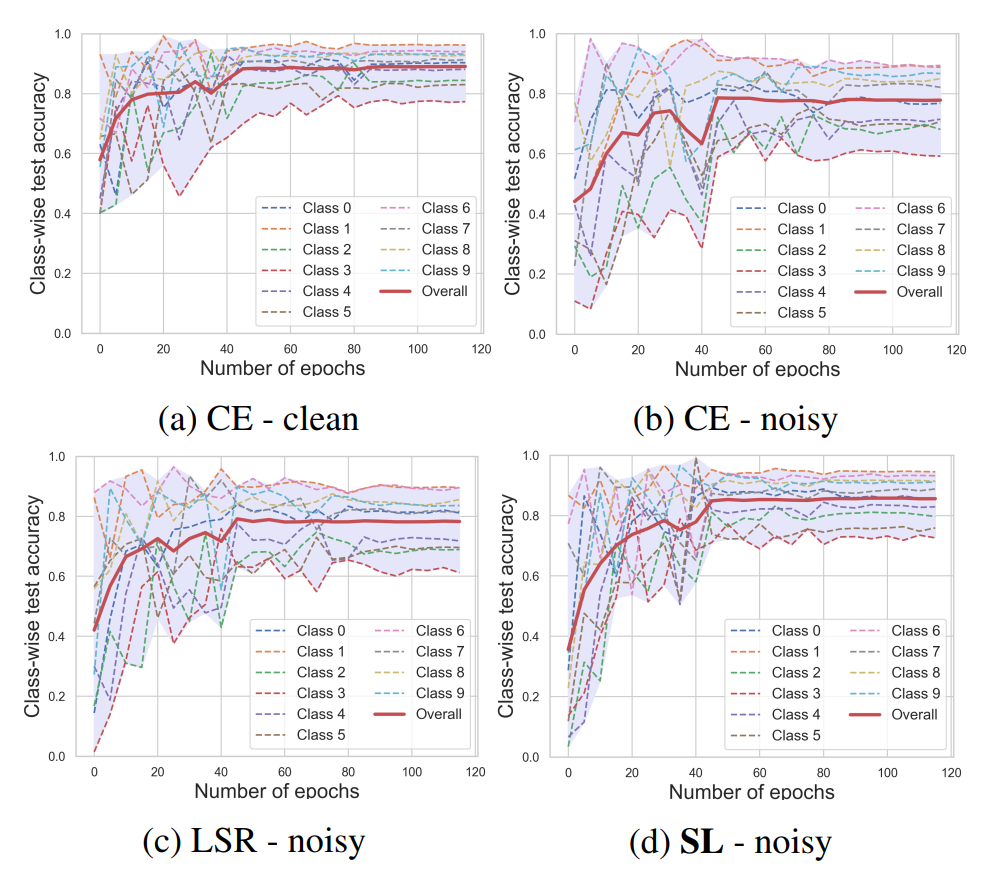
如何在有噪声标注的数据集上进行训练是一直受到工业界关注的问题,也产生了很多不错的工作。具体到分类任务上来看,论文作者发现使用交叉熵学习的深度神经网络会去过拟合那些简单类别而在一些困难类别上欠学习。直觉上,交叉熵需要额外的一项来促进困难类别的学习,更重要的是,这一项应该对噪声有容忍能力以避免过拟合噪声标签。受到KL散度的启发,论文提出了一种Symmetric cross entropy Learni
XGBoost的重要剪枝参数与波士顿房价数据集调参实战
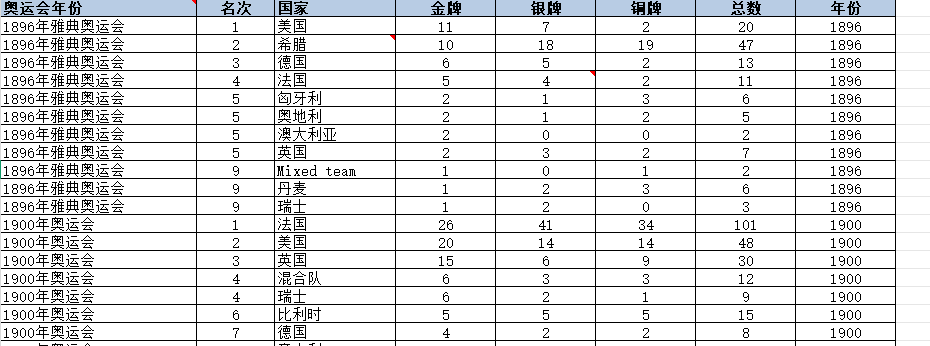
自1896年首届现代奥运会至2024年巴黎奥运会的完整奖牌统计信息,涵盖128年的体育竞技历史。3. **政策制定**:如德国奖牌数下降趋势(1984年108枚至2024年33枚)反映其体育战略调整需求;2. **社会经济**:通过奖牌分布与国家GDP、人口数据的相关性,探讨体育投入与产出的经济学模型;1. **体育科学**:可量化分析各国优势项目,如中国跳水(47金)、举重(38金)的长期竞争力
xgboost是华盛顿大学博士陈天奇创造的一个梯度提升(Gradient Boosting)的开源框架。至今可以算是各种数据比赛中的大杀器,被大家广泛地运用。接下来,就详细介绍一下xgboost的原理和公式推导。
今天给大家带来的复现内容是CHARLS数据库的一篇横断面研究文章,文章统计方法部分包括了①PSM前后基线差异性分析、②匹配后的回归分析。这些统计方法风暴统计快速一站式搞定,零代码操作,新手小白也可以轻松上手完成!今日文章分为两部分复现文章介绍风暴统计平台快速复现1.复现文章介绍案例文献是一篇基于CHARLS公共数据库的一项横断面研究,旨在评估中国慢性肾病患者(CKD)跌倒的患病率和风险。慢性肾病患
这里仅仅介绍一下AI图像识别App的实现原理,AI的基础技术细节不在本文讨论范围。。我们都知道,人工智能AI的基本原理是事先准备好样本数据(这里指的是图片)及数据的标注信息(如图片中的人物是高兴、愤怒、哭泣等图片的判定信息),。有了这份训练集数据,当下次我们输入一张新的图像时,AI算法根据训练集数据就能判断出图片中的人物的具体表情,这样就能对图片进行初步的分类。当然,判断的准确率和样本数量是有关系
分组最小角回归(Group Lasso)是一种用于回归分析和特征选择的统计方法,它由Yuan和Lin在2006年提出。Group Lasso扩展了传统的Lasso(Least Absolute Shrinkage and Selection Operator)方法,后者是一种通过来进行回归参数估计和特征选择的技术。Group Lasso的主要创新在于它,而不是像传统Lasso那样独立地选择每个特征
α算法是比较古老、原始和简单的流程发现算法,能够处理发现并发(concurrency)的能力,但在实践中不适用,因为存在一些问题(处理噪声、不频繁/不完整行为、复杂路由结构等)。这节介绍α算法,可以理解流程发现的内涵,并引出流程发现的挑战一、α算法1、基于日志的顺序关系先引入基于日志的活动顺序关系。定义1(基于日志的顺序关系,Log-based ordering relations)令是定义在活动
作者: Sebastian Raschka, PhD在这篇文章中,我想向您展示如何将预训练的大型语言模型(LLM)转变为强大的文本分类器。为什么专注于分类?首先,将预训练模型微调为分类器提供了一种温和而有效的微调入门方式。其次,许多现实世界和商业挑战都与文本分类有关:垃圾邮件检测、情感分析、客户反馈分类、主题标注等等。将GPT模型转变为文本分类器我非常激动地宣布,我的新书《从零开始构建大型语言模型
稀疏子空间聚类(Sparse Subspace Clustering, SSC)是一种处理高维数据的聚类方法,特别适用于当数据分布在多个低维子空间上的情况。SSC 利用了稀疏表示的概念来估计数据点之间的关系,并以此构建相似度矩阵,最终通过谱聚类技术将数据点分配到各自的子空间中。稀疏子空间聚类 (SSC)基本概念假设有一组数...
ML基础-分类模型的评估指标,注意2分类与多分类
汇编内容分为七个部分,包括综合数据、各地区粮食和油料、棉烟糖料、蚕茧水果、肉禽蛋奶、蔬菜以及畜产品的成本和收益数据。特别指出的是,全国性数据中并未包含香港、澳门特别行政区和台湾省的数据。在具体数据方面,“三种粮食平均”指的是稻谷、小麦、玉米的平均成本和收益;此外,对于“规模生猪”、“规模肉鸡”、“规模蛋鸡”、“规模奶牛”,汇编中提供了不同规模(小规模、中规模和大规模)的平均数据。蔬菜的平均成本和收
推荐系统经典论文文献及业界应用列了一些之前设计开发百度关键词搜索推荐引擎时, 参考过的论文, 书籍, 以及调研过的推荐系统相关的工具;同时给出参加过及未参加过的业界推荐引擎应用交流资料(有我网盘的链接), 材料组织方式参考了厂里部分同学的整理。因为推荐引擎不能算是一个独立学科,它与机器学习,数据挖掘有天然不可分的关系,所以同时列了一些这方面有用的工具及书籍,希望能对大家有所帮助
ARIMA(自回归移动平均)模型是一种常用的时间序列分析方法,可以用于分析并预测经济增长等时间序列数据。以下是使用ARIMA模型对中国GDP增长进行分析和预测的步骤:数据收集和预处理:收集中国GDP增长的时间序列数据,并将其转换为稳定的时间序列数据,以便进行后续分析。这通常涉及到去除趋势和季节性因素。模型拟合:使用ARIMA模型对稳定的时间序列数据进行拟合,以找出最佳的模型参数。ARIMA...
安装Qlib包在安装qlib包过程中遇到的问题和解决办法在安装qlib包过程中遇到的问题和解决办法官方链接:https://github.com/microsoft/qlib直接pip install qlib遇到如下报错:
朴素贝叶斯(Bayes)算法例题
Logistic回归(Logistic Regression)是一种广泛应用于统计学和机器学习领域的分类算法,尤其适合于二分类问题。它的目的是找到一个能够预测目标变量的概率分布的模型。
如上,K-S检验(柯尔莫戈洛夫-斯米诺夫)->是适用于大样本的正态性检验(样本量>2000)->因子列表(分类变量)(夏皮洛-威尔克)->适用于小样本的正态性检验。:显著性P因变量(连续性变量)茎叶图就是直方图顺时针旋转90度。可见,非正态分布(丝毫不搭边)
距离判定的方式也可以采用其他判定方式实现,比如对八叉树分块中的局部点云特征值(反光强度分布、曲率)等等进行判别,因此可以根据实际场景进一步设计该算法。比较依赖人工参数设定,不同的激光雷达传感器所设定的参数不一样,尤其是在点云密度分布一样的传感器其效果差别更大。具有很强的鲁棒性及聚类效率,不用针对整个点云数据即可实现聚类,可以适应绝大多数点云聚类场景。其实就是 cloudcompare 的这个聚类功
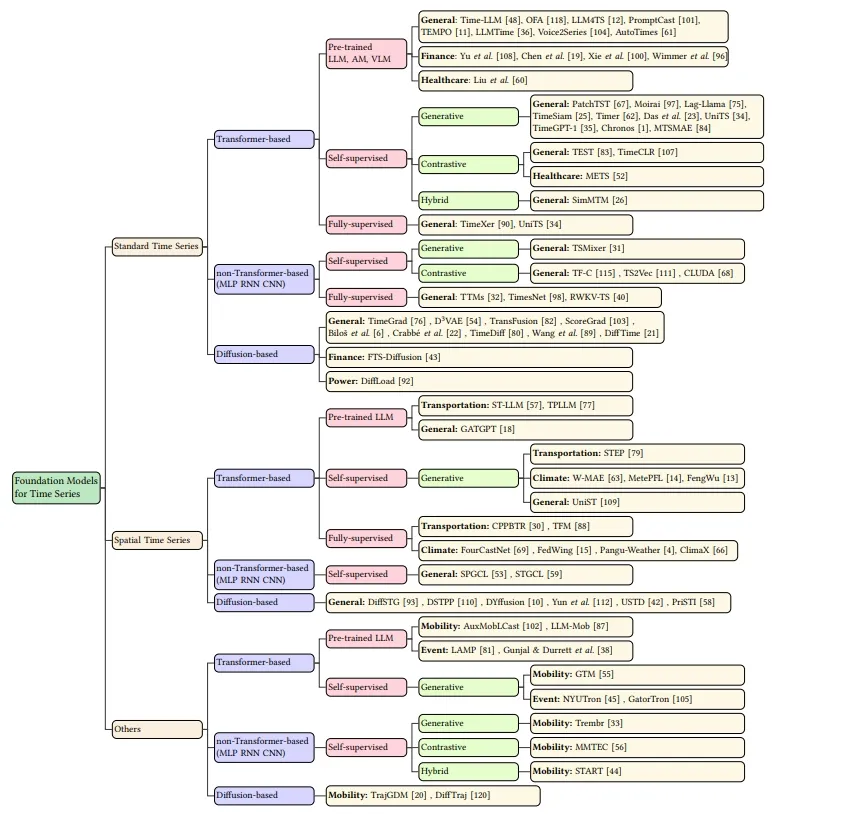
时间序列分析是数据挖掘社区中的焦点,是提取对无数实际应用程序至关重要的有价值见解的基石。基础模型 (FM) 的最新进展从根本上重塑了时间序列分析的模型设计范式,在实践中推动了各种下游任务。这些创新方法通常利用预先训练或微调的 FM 来利用专为时间序列分析定制的通用知识。在本综述中,目标是提供用于时间序列分析的 FM 的全面且最新的概述。虽然之前的综述主要关注 FM 在时间序列分析中的应用或流程方面
通过这次比赛的学习,算是初步了解了kaggle的整个流程。特征工程其实做得不够,特征太多了,可以做一下特征选择的工作模型也没有经过调参验证只是用了传统的机器学习模型,没有尝试深度学习模型,或许能减除特征工程这步如果有时间的话,可以再做一下后续的工作。
原点回归指令ZRN S1 S2 S3 D:S1原点回归速度,S2爬行速度,S3 DOG(零点)信号,此信号为输入信号X,D0脉冲输出端子(只能是Y0、Y1、Y2)例子:ZRN K1600 K400 X011 Y0原点回归过程解析原点回归过程:电机以原点回归速度启动运行,碰到DOG信号瞬间,电机由原点回归速度减小到爬行速度,离开DOG信号瞬间,脉冲当前值寄存器(Y0当前值寄存器是D8340,Y1是D
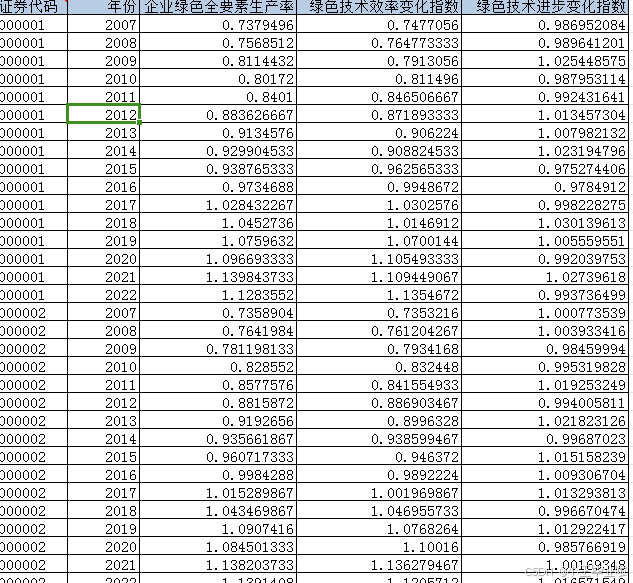
它不仅关注经济效益,还强调环境效益,体现了绿色发展理念。在测算过程中,劳动投入以企业员工数作为代理变量,资本投入以企业固定资产净额作为代理变量,能源投入则以企业所在城市工业用电量按企业从业人员占城市城镇人员就业比重进行换算作为代理变量。期望产出以企业营业收入作为代理变量,而非期望产出则以企业从业人员占所在城市城镇人员就业比重对“工业三废”即工业二氧化硫、工业废水、工业烟粉尘排放量进行换算,作为企业
在机器学习领域,特征选择是至关重要的一步,它有助于提高模型的泛化能力、减少过拟合,并提升模型的解释性。LASSO回归,作为一种引入L1正则化的技术,不仅能够进行有效的特征选择,还能处理特征间的多重共线性问题,是特征选择的强大工具。
数据集概述同质性图:Cora、CiteSeer和PubMed是三种常用的引用网络[1]。我们遵循传统的半监督设定[2]来划分数据集。此外,Computer和Photo是公共购买网络[3],CS和Physics是公共作者网络[3],我们采用训练/验证/测试划分为60%/20%/20%的标准[4]。我们还使用了Wiki-CS[5],该数据集是由计算机科学论文组成的引用网络,我们使用[5]的划分异质性图
多模态情感识别旨在识别多种模态中每个话语的情感,这在人机交互应用中越来越受到关注。当前基于图的方法未能同时描述对话中的全局上下文特征和局部多样的单模态特征。此外,随着图层数量的增加,它们很容易陷入过度平滑的情况。
根据相关统计数据,2010年,上市公司研发支出总额约为560亿元,2011年增至995亿元,2012年为1313亿元,2013年为1516亿元,2014年为1725亿元,2015年为2279亿元,2016年为2808亿元,2017年为3257亿元,2018年为3589亿元,2019年为4000亿元,2020年为4500亿元,2021年为5000亿元。在研发人员数量方面,2021年,行业研发人员总数
深度置信网络(深度信念网络Deep Belief Network)DBN回归预测-MATLAB代码实现
故障诊断是服务稳定性的重要一环,在工业界有非常丰富的应用场景。过去运维人员诊断根因常常需要人工浏览多种监控指标找关联关系,构建服务拓扑以分析故障传播等工作,非常耗费人力。是否有模型可以自动的分析多维时间序列之间的关联关系,推导根因呢?来自北京大学、中山大学的研究者们所带来的工作:《AutoMAP: Diagnose Your Microservice-based Web Applications
时间序列数据存在于现实世界系统和服务的每一个角落,从天空中的卫星到人体上的可穿戴设备。通过提取和推断这些时间序列中的有价值信息来学习表示,对于理解特定现象的复杂动态并做出明智的决策至关重要。有了学习到的表示,我们可以更有效地进行许多下游分析。在几种方法中,深度学习在从时间序列数据中提取隐藏模式和特征方面展现了卓越的性能,而无需手动特征工程。本文首先基于三个设计最先进的通用时间序列表示学习方法的基本
文章目录一、集成学习二、bagging2.1 基本描述一、集成学习多个小模型,通过最后的决策算法来决定最后的结果。集成方法常分为两类:(1)averging methods:平均法的原则是: 独立的构建几个学习器,然后平均他们的预测。通常,组合的学习器要比任何一个单个的学习器要好,因为它降低了方差。其中的代表:bagging 方法,随即森林(2)boosting methods:学习器依次构建(递
1.背景介绍强化学习(Reinforcement Learning, RL)是一种人工智能技术,它旨在让智能体(如机器人、软件代理等)在环境中自主地学习和做出决策,以最大化累积奖励。决策树(Decision Tree)是一种常用的机器学习算法,它可以用于分类和回归任务。在本文中,我们将讨论如何将决策树与强化学习相结合,以实现智能决策和策略优化。决策树是一种简单易理解的模型,它可以通过递归地...
时间序列森林(Time Series Forest, TSF)模型将时间序列转化为子序列的均值、方差和斜率等统计特征,并使用随机森林进行分类。TSF通过使用随机森林方法(以每个间隔的统计信息作为特征)来克服间隔特征空间巨大的问题。训练一棵树涉及选择m正在上传…重新上传取消 个随机区间,生成每个系列的随机区间的均值,标准差和斜率,然后在所得的3m正在上传…重新上传取消 个特征上创建和训练一棵树。..
ModuleNotFoundError: No module named 'pefile'
自注意力子层巧妙地运用点积注意力机制,为每个位置的输入序列编织独特的表示,而线性前馈神经网络子层则汲取自注意力层的智慧,产出富含信息的输出表示。梯度消失与模型退化之困得以解决:Transformer模型凭借其独特的自注意力机制,能够游刃有余地捕捉序列中的长期依赖关系,从而摆脱了梯度消失和模型退化的桎梏。在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面
Part2稀疏偏最小二乘判别分析(sPLS-DA)sPLS-DA(Sparse PLS discriminant analysis)是PLS-DA的一种特殊情况,同时包含变量选择和分类的过...
本文学习自罗静初老师写的双序列比对的论文
1.由于是多表,所以要先把其他表与train合并。根据train和其他表共有的某一列特征值中,选择一个共有列作为key然后进行合并。由于test的数据处理后也不能让行有变化,所以进行合并之前,其他表要先进行去重。2.合并后进行缺失值处理,使用平均值还是众数还是前后值要根据不同情况来分析,就比如油价就应该按前后值填充。2.对xgb_model训练的时候要先把Y_train取log,最后X_test要
数据挖掘
——数据挖掘
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net




 2048 AI社区
2048 AI社区